Si vous avez suivi la série d’articles intitulée « Ce que ChatGPT fait à la veille« , il ne vous aura pas échappé que je reviens à plusieurs reprises sur ce que les grands modèles de langage (ou LLM’s) impliquent quant au traitement et à l’analyse de corpus documentaires. Globalement, j’évoque les possibilités suivantes :
- Résumé d’un document ou d’un corpus de documents
- Extraction d’entités nommées d’un document ou d’un corpus de documents. C’est par exemple la première étape de ce que fait Geotrend.
- Extraction de concepts et thématiques d’un document ou d’un corpus de documents.
- Apprentissage de bases documentaires internes ou externes dans le but de les interroger/exploiter
Plusieurs services proposent déjà la possibilité de mettre en œuvre ces fonctionnalités sur des documents ou corpus documentaires spécifiques. Commençons par les plus simples qui, pour certains, ne sont que des versions de démonstration, mais qui n’en donnent pas moins une bonne idée de ce qui se prépare :
- LLM demo : Après avoir ajouté votre clé d’API (récupérable sur votre compte OpenAI, vous allez pouvoir lancer des requêtes par mots-clés dans plusieurs services :
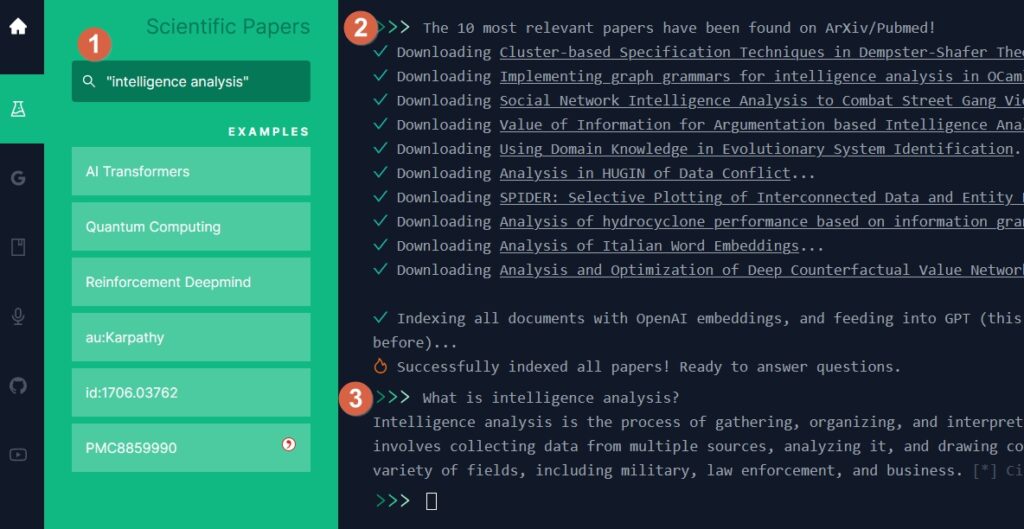
- Pubmed + Arxiv
- Google Docs
- articles de Substack
- podcasts et fichiers audios
- repos github
- vidéo Youtube (à venir)
A chaque fois le fonctionnement est le même. Le service charge les contenus textuels et les ingurgite. Une fois cela fait, vous pouvez questionner votre document en langage naturel.
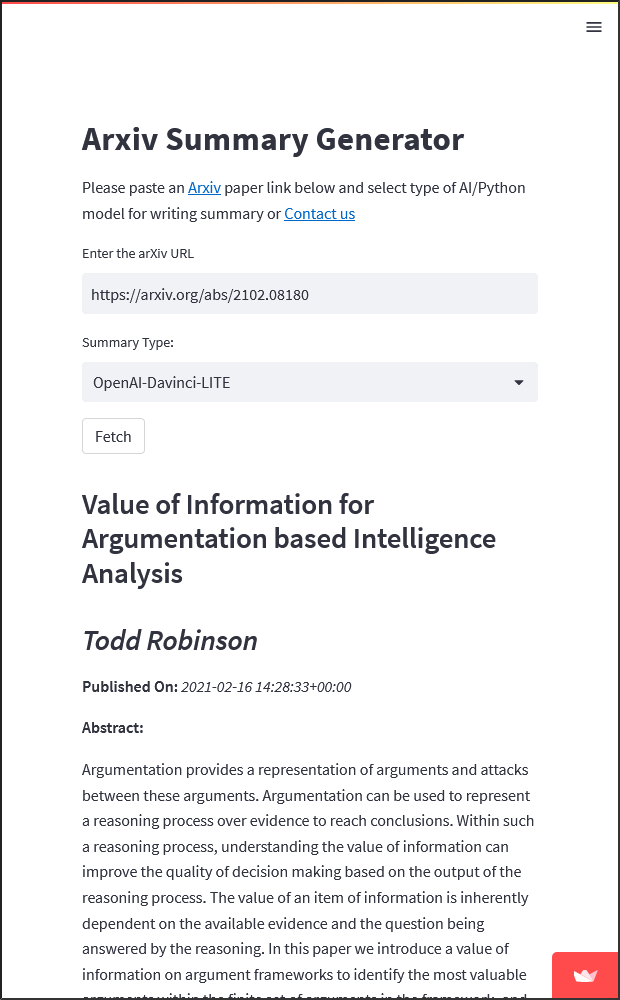
- Arxiv summary generator : Arxiv est une base de données open access regroupant plus de deux millions d’articles de recherche en sciences « dures ». Ce service permet de générer un résumé d’un article via ChatGPT. Pour cela il suffit de copier l’URL d’un article, de le coller dans le champ spécifique du service et de cliquer sur « Fetch ». Un résumé automatique vous est alors proposé en dessous de l’abstract original.
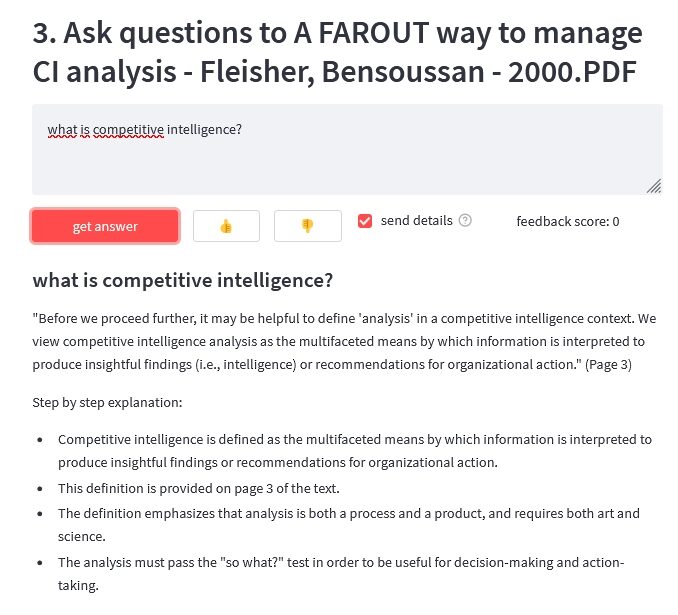
- Ask my PDF : Même idée que les précédents pour ce service qui a besoin de votre clé d’API Open AI pour fonctionner. Vous chargez ensuite un document PDF, puis, une fois indexé par le service, vous pouvez l’interroger en langage naturel.
- Humata : c’est le plus avancé des cinq services présentés dans ce premier billet. Il a la même vocation que les trois autres mais dispose d’une interface et de fonctionnalités plus avancées. Il est gratuit pour les documents de moins de 20 pages ce qui permet déjà de bien le tester. Les documents sont chargeables et interrogeables un à un. Par exemple sur cet article de Nicolas Lesca consacré aux signaux faibles et à la méthode Puzzle j’ai posé trois questions à Humata :
- Qu’est-ce qu’un signal faible?
- Qu’est-ce que la méthode puzzle?
Comme vous pouvez le constater, les résultats sont plutôt très bons, avec un gros avantages sur les autres outils : Humata permet de revenir aux extraits qu’il a sélectionné afin de générer sa réponse.

- Troisième question posée sur ce même article : résume cet article en 5 points. Voici le résultat :
- 1. La méthode Puzzle® est un moyen d’exploiter les signaux faibles et a été développée par une équipe de chercheurs du CERAG-CNRS.
- 2. L’article présente une fiction sur la Chine et le personnage de Lili Zheng, qui est chargé de recueillir des informations utiles pour le ministre de l’Économie.
- 3. Le ministre Wang a identifié quatre forces principales qui pourraient mener à une explosion en Italie: une forte pression fiscale, une faible croissance économique, une révolte sociale et une remise en cause des relations industrielles du travail.
- 4. Les signaux faibles sont pertinents, anticipatifs, fragmentaires, noyés dans des données brutes, insolites et qualitatifs.
- 5. L’Italie est confrontée à des mouvements sociaux, une très forte pression fiscale, des pressions de la Ligue du Nord, un coût exorbitant des élus politiques, un chaos au gouvernement, une très faible croissance économique, une modification du statut des travailleurs italiens, un discrédit de la classe politique et un rôle de l’Internet, ce qui pourrait mener à une explosion de l’Italie.
Ajout du 05/03/2023
- ChatPDF : après avoir téléchargé un document PDF, ce service commence par vous en proposer un résumé en trois points. Il vous est ensuite possible d' »interroger » votre document en langage naturel.

Mais nous irons plus loin dans le prochain billet : imaginez que vous puissiez interroger, analyser, résumer votre base documentaire personnelle, les emails reçus de telle personne, un dossier partagé, le contenu d’une GED ou d’une base Sharepoint. C’est la promesse de services qui émergent déjà et ne manqueront pas de se déployer très rapidement dans les mois qui viennent.
Comme on le constate, tout ce qui est écrit devient donc requêtable et exploitable en langage naturel. Bien qu’il soit encore difficile d’envisager tout ce qui émergera de ces possibilités, ces services (dont certains auront probablement disparu dans 3 mois), en sont une bonne préfiguration.
Stay (fine) tuned!


Je suis complètement d’accord avec ton orientation de fin de billet. J’ai formulé exactement de cette façon les possibilités de ChatGPT sur la veille en réponse à quelqu’un qui me « chalengeait » sur un dossier issu de l’open source. Je pense que ce que nous capitalisons à une grande valeur et si nous gagnons du temps sur son traitement, c’est un gain non dimensionné si l’on prend en compte que les personnes ayant la mémoire ne sont pas ou plus toujours là. Faire des résumés, des synthèses sur de grosse masse de données, j’y vois également un gain important sur le potentiel que nous montre ChatGPT.
Merci, Christophe, tu nous montres une fois de plus que tu as toujours un coup d’avance sur les autres communicants de ce métier.
Merci Gaby 🙂
Les mois à venir vont être passionnant!