La phase de collecte c’est un peu le cœur du réacteur de toute veille. C’est le moment où l’on va rechercher les sources qui alimenteront le dispositif en contenus nouveaux, jour après jour. C’est aussi là que l’on déploiera les outils permettant de surveiller ces sources, quelles qu’elles soient. Soyons clair, pour l’instant, ChatGPT n’est pas un service qui permet d’effectuer la moindre surveillance, en revanche, il peut être très utile dans la partie d’identification de sources.
Généralement, le sourcing consiste à identifier les mots-clés que l’on utilisera ensuite dans un moteur afin de rechercher les sources utiles. Il est possible par exemple de demander à ChatGPT : « donne moi le champ sémantique de l’industrie nucléaire. »
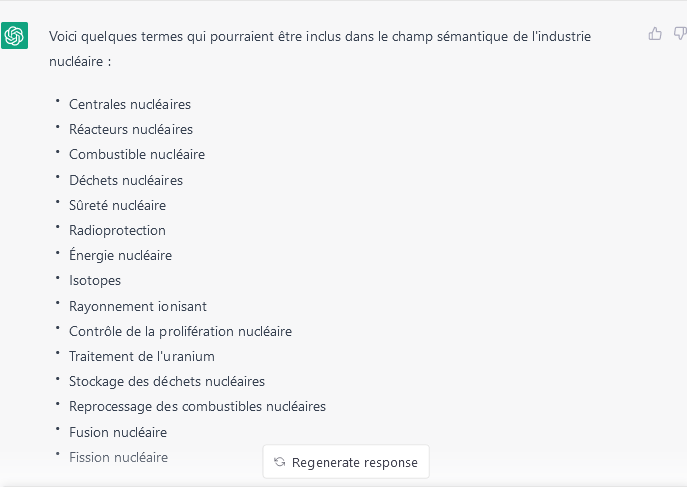
Ou encore : « donne moi les mots-clés les plus utilisés lorsqu’on parle de l’industrie nucléaire. »

Une fois des mots-clés trouvés, on va lui demander de nous fournir des synonymes. Par exemple ici « synonymes de radioprotection » :

Tout n’est pas parfait mais c’est tout de même un bon début.
On peut aussi lui demander des thésaurus si l’on souhaite aller plus loin : « Indique moi des thésaurus ou vocabulaires contrôlés relatif à l’énergie nucléaire »

On peut également lui demander des noms d’acteurs à suivre dans un secteur spécifique. Par exemple : « Donne moi 10 acteurs importants à suivre dans le domaine de l’énergie nucléaire, en France et en Europe. Organismes privés ou publiques. »

Complété par : « Indique moi leurs sites web »

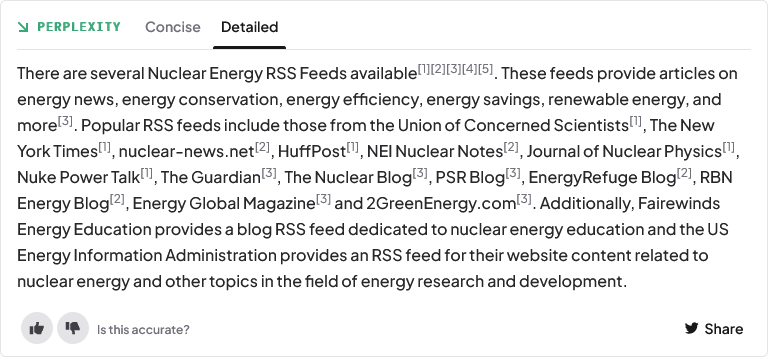
J’ai bien évidemment tenté de demander directement des listes flux RSS sur la même thématique mais les résultats n’étaient pas bons. Les flux proposés ne fonctionnaient pas. Je suis alors passé sur le service Perplexity.ai, une interface d’interrogation du web qui mixe les résultats d’un moteur de recherche traditionnel avec ceux issus d’un chatGPT ayant la possibilité d’exploiter les sites web. En effet, pour l’instant, ce dernier ne peut pas se connecter au web. La limite actuelle de cet outil est que les interrogations et résultats sont en anglais. Il donne néanmoins une bonne idée de ce qui va arriver. Ainsi, à la requête « nuclear energy rss feeds » j’ai obtenu des résultats intéressants :
On peut aussi demander à chatGPT de générer une requête avancée pour Google : « Crée une requête Google me permettant de trouver des organisations publiques ou privées, en France ou dans l’union européenne, intéressantes à suivre dans le cadre d’une veille sur l’énergie nucléaire. » Réponse :
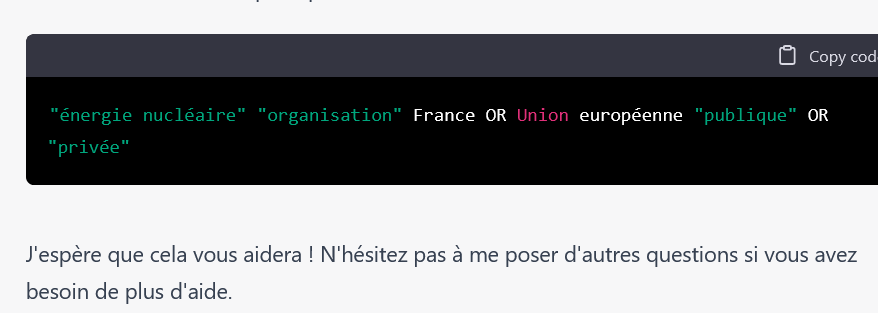
Je ne l’aurai pas forcément formulée ainsi mais les résultats sont plutôt bons comme vous pourrez le constater. Notez que je n’ai pas affiché les autres conseils d’optimisation proposés par le service et qui n’étaient pas mauvais.
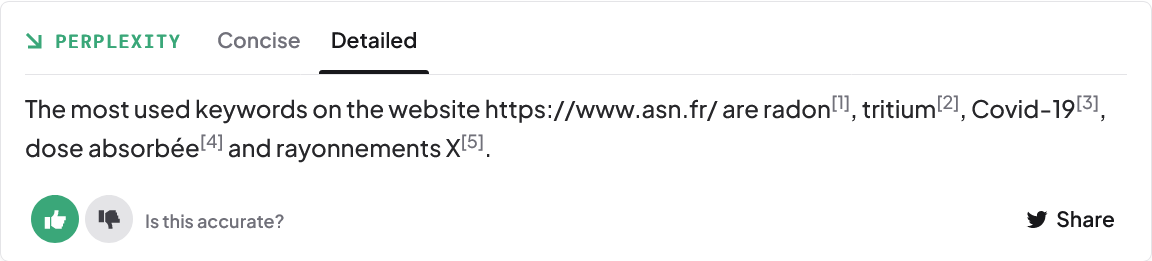
Revenons sur Perplexity.ai et voyons ce que l’on peut tirer de cette possibilité de connexion au web dans le cadre du sourcing. J’ai tenté par exemple cette question : « liste les mots-clés les plus utilisés sur le site : https://www.asn.fr/ supprime les stopwords »
Ou encore : « liste les 10 mots-clés les plus utilisés sur le site :https://cds.cern.ch supprime les stopwords ».
Sans être exceptionnels, les résultats laissent tout de même augurer d’intéressantes perspectives pour l’avenir.
Enfin, et ce n’est pas aussi anecdotique que ça en a l’air, chatGPT peut nous aider à trouver les mots qui nous échappent. Voici par exemple une question que je lui ai posée durant l’écriture de l’article précédent : « Quel moteur s’est déjà positionné comme un moteur de réponse, concurrent de Google? Un moteur plus ancien que Duckduckgo créé par un mathématicien je crois. ». Sa réponse (qui était la bonne) :

Comme on le constate donc, les modèles de langage possèdent un fort potentiel dans cette phase de collecte et en particulier dans la partie sourcing. Cette utilisation est très liée à la capacité d’être créatif dans ses questions et à la manière de les formuler. Ce qui est plutôt rassurant pour nous les humains. L’ère du « prompt », c’est à dire de l’instruction donnée au système, désormais en langage naturel, est devant nous.
Par ailleurs, comme il a été mentionné précédemment, ces outils ne proposent pour l’instant aucune possibilité de surveillance de sources web ou autres, mais l’on peut déjà imaginer sans prendre trop de risques que, lorsque les modèles seront capables de traiter des contenus web en quasi temps réel, ils pourraient offrir des fonctionnalités assez similaires aux alertes Google actuelles. On pourrait par exemple leur demander :
- Fais-moi un point de situation quotidien sur la guerre Russie-Ukraine.
- Donne moi une synthèse hebdomadaire des risques d’augmentation des coûts de l’énergie en Europe
- Surveille et synthétise les annonces faites par mes concurrents en Asie du Sud-Est. Parce que le modèle de langage aura appris de vos contenus documentaires internes, vous n’aurez pas à lui préciser les noms de ces concurrents.
Il est essentiel que les éditeurs de solutions de veille traditionnelles prennent le train en marche s’ils ne veulent pas se voir déborder par des solutions techniques et fonctionnelles reposant sur des bases très différentes des leurs. Traiter le texte comme n’importe quelle « data » implique une infrastructure et des contraintes probablement assez différentes de celles sur lesquelles ils fonctionnent actuellement. Mais il est probable que ces éditeurs suivent déjà ces évolutions et ont anticipé ces changements.
A NOTER : je me concentre pour l’instant sur l’exploration des usages potentiels des modèles de langage. Le dernier article de cette série reviendra bien évidemment sur leurs limites et les risques qu’ils sont susceptibles de faire courir aux veilleurs et analystes.
A NOTER : j’ai mis en place une page web sur laquelle je partage les « outils » permettant d’intégrer chatGPT au quotidien (extensions, plugins, etc). Et il y en a de nouveaux tous les jours…


3 commentaires