Lors du récent recensement de services de traitement de corpus documentaires via IA que j’ai effectué, dans le but d’en faire un comparatif, j’en ai identifié une quinzaine d’autres spécialisés sur l’exploitation de l’information scientifique et technique. Il m’a paru utile de les évaluer à leur tour, d’une part, parce que depuis une vingtaine d’années déjà, je forme des professionnels à la recherche et la veille scientifique, et que cela les intéresse au premier chef, d’autre part, parce qu’il me parait intéressant de voir comment ce type de corpus est exploité par les modèles de langage, ce que l’on peut concrètement en tirer. J’ai donc créé un nouveau tableau comparatif, sous Notion, que je vous partage ici.

Modalités du test effectué
La promesse de ces solutions est de permettre aux étudiants et chercheurs de trouver rapidement des publications utiles à leurs travaux, tout en les aidant à les exploiter au mieux grâce aux modèles de langage.
Les critères retenus pour ce comparatif sont les suivants :
Critères généraux :
- Modèle de langage : quel sont les modèles de langage utilisés par ces services. Notez que, sauf erreur de ma part, une moitié des éditeurs ne le précisent pas.
- Sources : bases de données et/ou moteurs de recherche de contenus scientifiques utilisés pou remonter des publications
- Format de sortie (rédaction) : quels sont les formats de sortie proposés (si le service dispose d’une fonctionnalité de rédaction)
- Gestion de la température : possibilité de modifier le niveau de « créativité » du modèle de langage utilisé
- Gestion de la langue : modification de la langue de la réponse
- Extension pour navigateur : possibilité d’utiliser une extension pour ajouter des publications ou éléments de publication à son interface
- Distribution : gratuit, freemium, payant
- Tarif préférentiel pour les chercheurs et universitaires
- Fonctionnalités collaboratives : le service permet de travailler à plusieurs (par projets)
- Commentaire
- Note : il s’agit d’une note d’appréciation des services liée aux fonctionnalités proposées, ainsi qu’à mon ressenti à l’usage
Critères fonctionnels
Une vingtaine ont été pris en compte :
- Comparateur de documents : le service permet-il de comparer les contenus de plusieurs documents
- Dialogue monodoc : le service est-il conçu pour dialoguer avec un seul document
- Dialogue multidoc : le service est-il conçu pour dialoguer avec un corpus de documents
- Extraction de concepts : le service permet-il d’extraire des concepts d’un document ou d’un corpus documentaire
- Extractions de données : le service permet-il d’extraire des contenus spécifiques (protocoles mis en oeuvres, population étudiée, région, limite de l’étude, références citées,…)
- Générateur de citations : Le service offre-t-il une fonctionnalité permettant de générer automatiquement des citations à partir de documents ?
- Organisation de la recherche : Le service propose-t-il des fonctionnalités permettant de gérer les résultats des recherches effectuées dans l’interface ?
- Prise en charge des brevets : Le service permet-il de gérer, rechercher ou analyser des informations relatives aux brevets ?
- Proposition de documents relatifs : Le service propose-t-il des publications similaires à celles déjà ajoutées à l’interface ?
- Recherche d’articles par concepts : Le service extrait-il les concepts-clés des documents et en propose-t-il d’autres relatifs ?
- Recherche de documents : Le service dispose-t-il d’un moteur de recherche ou d’un chatbot permettant de rechercher des publications ?
- Rédaction assistée par IA : Le service propose-t-il un espace rédactionnel et une assistance à l’écriture via IA ?
- Résumé automatique : Le service propose-t-il des fonctionnalités de résumé automatique de publications ou de parties de publications ?
- Suggestion de questions de démarrage :Après avoir « analysé » une publication, le service propose-t-il plusieurs questions pertinentes (a priori) permettant d’entamer le dialogue ?
- Suggestion de passages pertinents : Le service propose-t-il les passages pertinents d’une ou plusieurs publications en fonction d’une question posée ou d’une sélection textuelle ?
- Prise de notes : Le service propose-t-il une fonctionnalité de prise de notes pour accompagner l’exploitation des documents ?
- Upload de documents : Le service permet-il à l’utilisateur de charger les documents présents sur son poste afin de les exploiter ?
- Recherche web : Le service permet-il aussi de lancer des recherches sur le web ?
- Renvoi vers les documents : Le service permet t-il, à partir du texte qu’il a généré, de remonter aux documents sources.
- Renvoi vers les extraits : Le service permet t-il, à partir du texte qu’il a généré, de remonter aux extraits de documents sources qu’il a utilisé.
Analyse des résultats
Afin de pouvoir tirer parti de ce tableau, je l’ai exporté en fichier .csv. et, plutôt que d’opter pour Excel pour générer des graphiques, j’ai choisi d’explorer les capacités de traitement de ChatGPT 4 (code interpreter). Voici les étapes que j’ai suivies et les prompts, très simples, que j’ai employés. :
- Upload du fichier .csv
- Prompt : lis ce fichier
- Prompt : Quels types de traitements statistiques peux-tu effectuer sur ce fichier ?
- Prompt : Génère tel graphique (copier-coller de ceux cités dans sa liste de propositions)

Les fonctionnalités
Nous débutons par un nuage de mots-clés illustrant les 20 caractéristiques analysées, leur taille étant proportionnelle à la fréquence de leurs mentions.

La seconde représentation graphique est un diagramme en barre qui permet de voir quelles sont les fonctionnalités les plus représentées dans l’ensemble des services pris en compte.
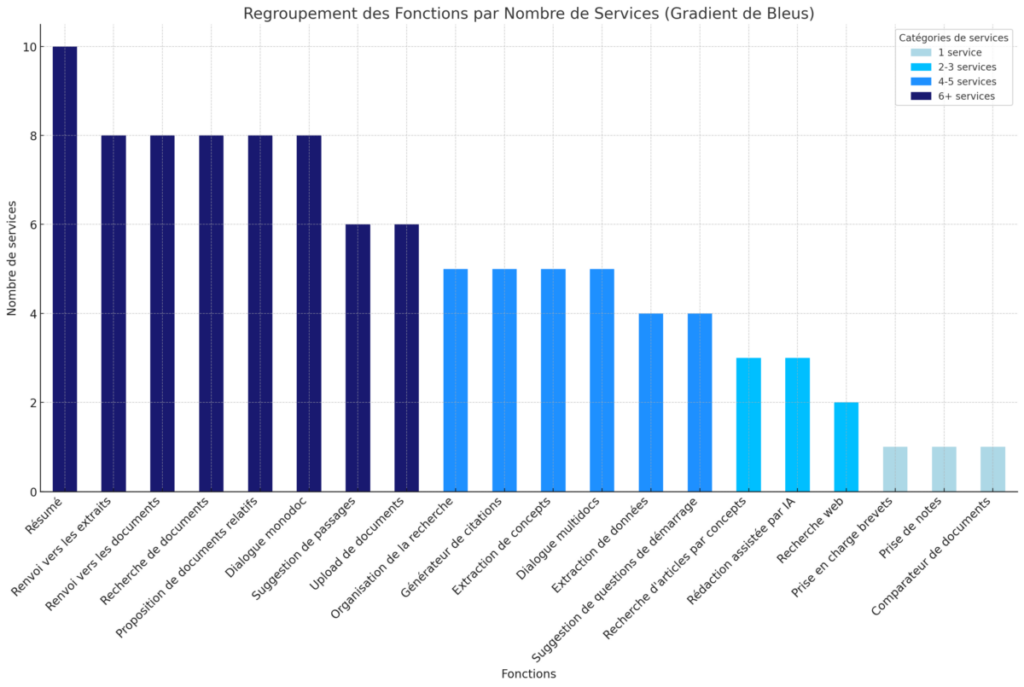
Sans surprise, on y constate que les résumés automatiques sont presque partout présents.
On retrouve ensuite un ensemble de fonctionnalités disponibles dans plus de la moitié des services étudiés. Il s’agit de :
- renvoi vers les extraits
- renvoi vers les documents sources
- recherche de documents (publications)
- proposition de documents relatifs
- dialogue monodoc
Ces fonctionnalités deviennent rapidement courantes, notamment dans les services axés sur le contenu scientifique. Cela marque une véritable commoditisation.
À l’inverse, certaines fonctionnalités sont actuellement rares. C’est le cas par exemple de :
- la prise en compte des brevets (mais d’autres services spécialisés les traitent déjà),
- la prise de notes : mais c’est une fonctionnalité basique qui peut facilement être ajoutée ultérieurement et ne demande pas de longs développements
- le comparatif de documents : nous avons affaire ici à une fonctionnalité potentiellement très utile puisqu’elle permet par exemple la comparaison des contenus de publications.
- SciSummary propose ainsi de comparer un ou plusieurs documents dans leur globalité, ou en se focalisant sur des sections qu’il extraira préalablement des articles. Il procèdera ensuite à la rédaction d’une synthèse mettant en évidence les éléments distinctifs identifiés dans chaque document.
Les services
Pour comparer les services, nous avons fait travailler ChatGPT sur deux représentations. La première est une « heatmap » qui permet de voir quels services sont les mieux dotés fonctionnellement parlant.
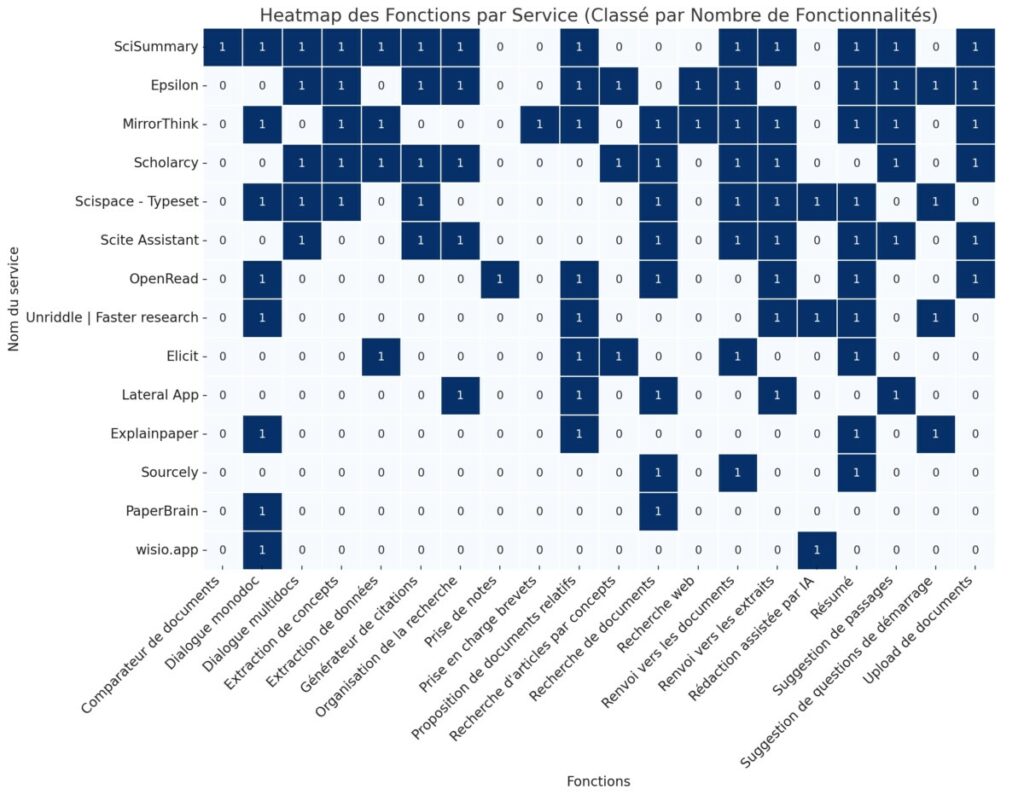
Cinq se détachent du lot :
- SciSummary (13)
- Epsilon (12)
- MirrorThink (12)
- Scholarcy (11)
- Scispace (10)
La seconde est un diagramme de Venn qui permet de comparer les champs fonctionnels de trois de ces services : Scholarcy, SciSummary et Epsilon. Nous avons volontairement mis de côté MirrorThink, qui propose d’intéressantes fonctionnalités, mais dont l’interface reste pour l’instant trop austère par rapport à ses concurrents. Nous aurions aimé ajouter Scispace mais un diagramme de Venn devient difficilement lisible avec 4 entrées.
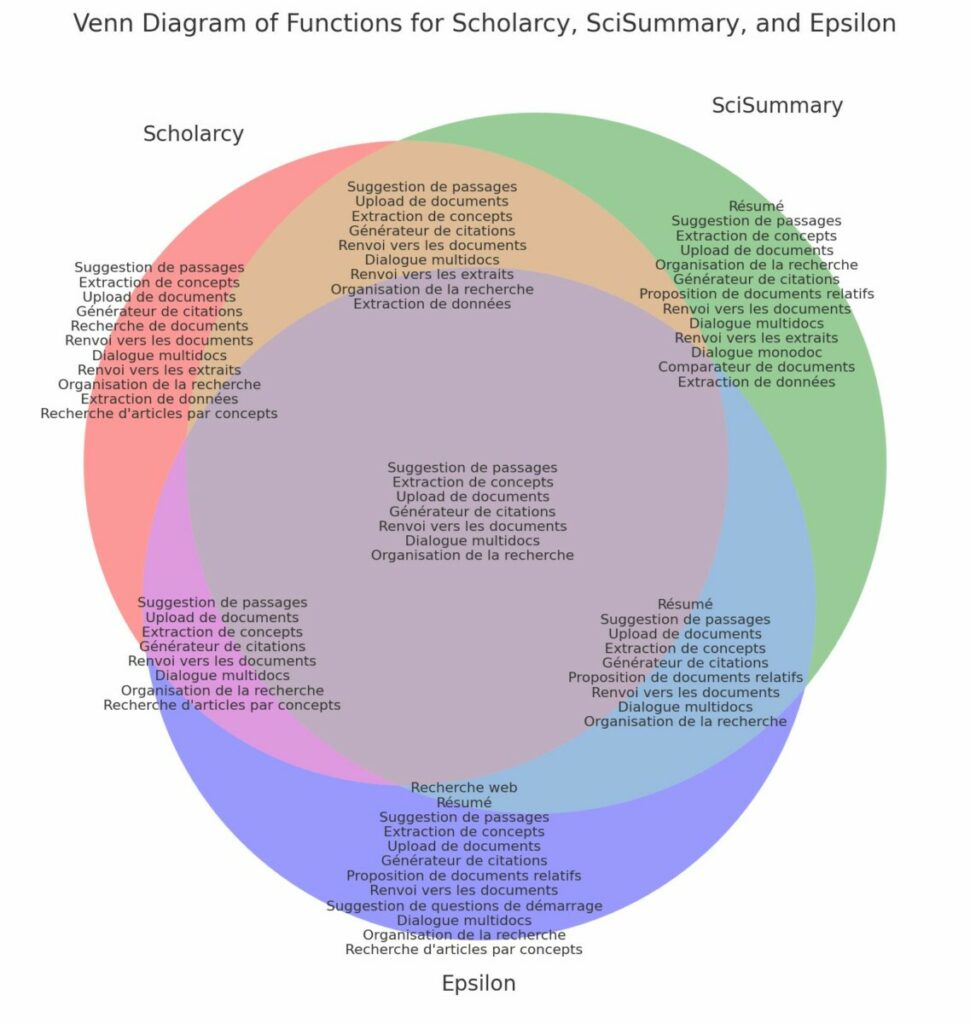
Comme on peut le constater, ils partagent de nombreuses fonctionnalités communes, mais aussi certaines fonctionnalités qui leur sont propres. Il faut s’attendre naturellement à ce qu’une course aux fonctionnalités les conduise rapidement proposer les mêmes possibilités. L’élément distinctif résidera alors dans l’expérience utilisateur (UX). A cet égard, OpenAI aurait tout intérêt à proposer rapidement une nouvelle interface tant certains de ses gros concurrents (Google pour ne pas le nommer) ont ici une expérience qui pourrait vite faire la différence.
Enfin, à l’issue du test, j’ai attribué une note à chacun de ces services en fonction de ses possibilités ainsi que de son ergonomie. Bien sûr, cette note reste subjective et j’ai donc demandé à ChatGPT 4 d’examiner une possible corrélation entre cette évaluation et le nombre de fonctionnalités offertes par ces services.
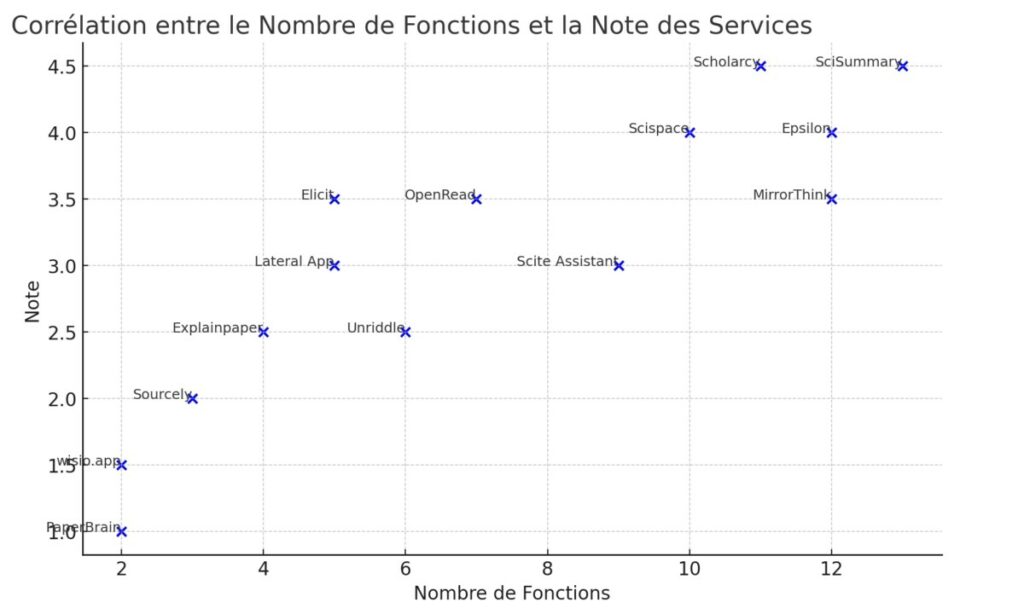
La note attribuée n’est donc pas toujours correllée au nombre de fonctionnalités proposées par chaque service, et c’est clairement l’expérience utilisateur qui amène Scispace à ce niveau de classement.
Limites de ces services
La principale limite de ces services est liée à la capacité des modèles de langage dont ils dépendent à interpréter des grandes quantités de texte. Ce que l’on appelle la « fenêtre de contexte ». Alors qu’elle était de 4000 tokens pour ChatGPT 3.5, elle a doublé pour ChatGPT 4 et lui permet de traiter environ 6000 mots d’un coup. Mais ChatGPT 4 Turbo, une version destinée aux développeurs, accessible via une API et lancée fin novembre 2023, propose déjà la possibilité de traiter 128 000 tokens d’un coup. Soit la taille moyenne d’un roman. Ou d’une petite thèse… La société Antropic a pour sa part révélé le mois dernier que son modèle Claude 2.1, rival de ChatGPT 4 Turbo, pouvait traiter jusqu’à 200 000 tokens. C’est donc d’une course à la puissance dont il s’agit, avec des impacts que l’on verra très rapidement sur les services analysés ici.

La seconde limite est celle liés aux sources prises en compte. Ces services annoncent souvent avoir accès à un corpus de 200 à 300 millions de publications. Le problème est qu’ils n’indiquent pas toujours quelles sont leurs sources.
L’autre limite, déjà évoquée, est liée à la lisibilité des interfaces et de ce que permettent ces services.
Alors quel service choisir ?
Difficile de dire si l’un de ces 5 services est meilleur qu’un autre. A titre personnel, j’en retiens plus spécifiquement deux. Dans cet ordre :
- Scispace, pour ces nombreuses fonctionnalités, son interface très claire et son extension Chrome permettant d’ajouter facilement des contenus dans sa bibliothèque et d’interagir avec les pages sur lesquelles vous naviguez.
- SciSummary, qui propose plus de fonctionnalités, mais ne propose pas d’extension de navigateur pour l’instant, et donc l’UX est un peu en dessous à mon sens.
Quoiqu’il en soit, je ne peux que vous encourager à tester les services qui font la course en tête, si vous souhaitez faire vos propres choix. Par ailleurs, il ne faut pas perdre de vue OpenRead et Scite qui, même s’ils sont pour l’instant plus limités fonctionnellement que leurs concurrents, évoluent de manière intéressante.
Conclusion
Faire ce type de comparatif est toujours une prise de risque lorsque les évolutions sont si rapides et que le marché n’a pas atteint sa maturité. C’est toutefois indispensable dans une démarche de veille tant il est important de comprendre ce qui se joue et notamment le potentiel d’usage de ces outils. C’est aussi la seule manière d’anticiper nos propres métiers de veilleurs, documentalistes. Ou l’indispensable « veille sur la veille ».


Waouh… super boulot merci