Dans les deux derniers articles consacrés aux modèles de langage que j’ai publiés, j’ai présenté plusieurs services permettant de traiter des documents ou des corpus documentaires, essentiellement au format PDF. Au fur et à mesure de la veille que j’ai effectué ces derniers mois sur ces sujets, j’ai pu constater l’émergence grandissante de ces services et j’ai choisi de les répertorier dans une base Airtable, à l’instar de ce que je fais déjà pour les intégrations des modèles de langage de type ChatGPT dans nos environnements de travail (plus de 350 intégrations recensées à ce jour et il en manque).
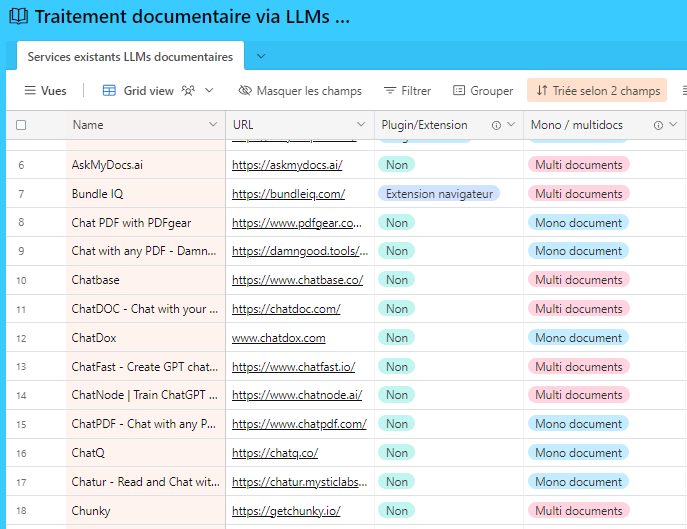
C’est ce tableau comparatif que je partage avec vous aujourd’hui. Il comporte déjà 50 entrées et peut être filtré par critères (filtrer/grouper) ou mots-clés (moteur de recherche).
Rappelons que ces solutions ont pour objectif annoncé de permettre d’entrer en discussion avec un document ou un corpus de documents. Par ce simple énoncé et à l’issue des tests que j’ai pu effectuer, il est évident que ces services, ou d’autres similaires, transformeront incontestablement notre relation avec la documentation au fil du temps, même si des améliorations demeurent nécessaires. Désormais, la documentation devient une entité avec laquelle nous pouvons dialoguer, échanger des idées et réfléchir ensemble, tout comme on le fait avec ses collègues et en gardant bien sûr à l’esprit que les modèles de langage ne raisonnent pas (mais résonnent).
Modalités du test effectué
Le test effectué a consisté à créer un compte sur chacun de ces services puis à « lancer le dialogue » autour d’un même document ou corpus de documents.
Les critères retenus pour le comparatif sont les suivants :
- Mono/Multidocs : le service est-il conçu pour dialoguer à partir d’un seul document ou d’un corpus de documents ?
- Plugin/extension : le service propose-t-il un plugin ou une extension, à intégrer, par exemple à son navigateur.
- Sources liées (services multidocs seulement) : le système indique-t-il de quels documents-sources il a extrait ses réponses ?
- Renvoi dans le document : le service permet-il de retrouver les passages d’un ou de plusieurs documents lui ayant servi à élaborer sa réponse.
- Gestion de la température : possibilité d’avoir des réponses plus ou moins créatives
- Modèle économique : gratuit, freemium, payant, …
- Sources de données : formats de documents acceptés ou types de sources acceptées (PDF, HTML, .docx, .txt, epub, vidéo, Slack, Notion, Google Drive,…)
- Orientation marketing :
- traitement documentaire orienté KM
- chatbot pour services clients
- Embedding : possibilité d’embarquer le chatbot créé sur un site web, par exemple pour permettre à des visiteurs de dialoguer avec des contenus que vous souhaitez partager avec eux.
- Modèle de langage : ChatGPT 3.5, ChatGPT 4, Claude, …
- Évaluation : j’ai choisi initialement de noter les services de 1 à 3 mais il faut plutôt considérer de fait la présence d’étoiles comme l’indicateur de services qui se démarquent des autres.
Quels services choisir ?
Ce travail avait initialement un objectif de recensement de services potentiellement utiles aux travailleurs du savoir que nous sommes, mais il serait incomplet sans une tentative d’extraire de ces tests les solutions les plus intéressantes. Voici donc les services qui m’ont paru les plus performants pour l’instant (car tout évolue très vite).
- Services monodocs :
- Ailyze : service et interface simple (désuète ?) proposant des fonctionnalités de dialogue avec le document bien pensées (cf. le « Conduct thematic analysis »)
- Sider AI : service « couteau suisse » décliné sous forme d’extension pour Chrome et d’app pour Windows.
- Upsum : propose par défaut un résumé pertinent pour chaque document téléchargé et en extrait les points clés.
- Services multidocs
- BundleIQ : facile à comprendre et utiliser. Accès aux documents sources un peu lent.
- Storytell.ai : interface simple à prendre en main. Extraction automatique de concepts d’un corpus. Résultats qualitatifs. Cf. la présentation que j’en avais faite ici.
- Cody : là encore un service accessible. L’accès aux documents sources est rapide et bien conçu. Pour plus de détails sur ce service, voir la présentation que j’en avais donnée ici.
Limites de ces services
Il est souvent frustrant de constater que les sources ne sont pas toujours citées correctement (lorsqu’elles le sont). Par ailleurs, les réponses peuvent parfois être très lentes, ce qui remet en question l’utilisation en mode « assistant de travail » que l’on peut espérer de ces services. Enfin, même lorsque leur fonctionnement est fluide et semble favoriser une exploration documentaire de qualité, il est impossible de leur faire entièrement confiance. La raison en est que nous ne pouvons pas vraiment cerner leurs limites et leurs angles morts, c’est-à-dire concrètement les documents ou parties de documents qu’ils n’ont pas utilisés pour élaborer leur réponse.
De l’ère de précurseurs à l’ère des curseurs
Il est clair que la multitude de services actuellement disponibles indique que nous vivons une période de « ruée vers l’or » qui ne perdurera pas. Comme c’est généralement le cas, bon nombre d’entre eux auront disparu d’ici à quelques semaines ou mois, soit parce qu’ils n’auront pas réussi à évoluer suffisamment vite en termes d’ergonomie et de fonctionnalités, soit parce qu’ils auront été rachetés. Un scénario n’excluant pas l’autre.
Mais gardons à l’esprit que nous n’en sommes qu’au début et qu’avec le temps, ces dispositifs intégreront de plus en plus de mécanismes nous permettant de mieux comprendre leurs choix et leur mode de fonctionnement. Actuellement, l’effet magique persiste, mais il deviendra rapidement indispensable de disposer d’une visibilité sur la manière dont ces systèmes opèrent au sein d’un corpus de documents : quelles parties de texte sont prises en compte et pourquoi celles-ci plutôt que d’autres dans l’élaboration de leur réponse.
Cet impératif de transparence laissera bientôt la place à un impératif de contrôle : comment puis-je influencer et orienter ces dispositifs pour mieux les exploiter en comprenant leurs biais, en y remédiant, en sélectionnant, en choisissant précisément les parties de texte à exploiter ou encore les documents à comparer, synthétiser, remixer, etc.
Je me risque donc à une prédiction : nous allons rapidement passer de l’ère des précurseurs à celle des curseurs. Pour parvenir à ce contrôle, nos interfaces vont en effet devoir se doter de fonctionnalités supplémentaires permettant cette interaction avancée avec les corpus documentaires. À ce jeu-là, comme toujours, c’est l’UX qui fera la différence.
Mise en garde : pour des questions de confidentialité, n’utilisez pas de documents internes à vos organisations pour tester ces services.


1 commentaire