Nous avons vu dans le précédent article que plusieurs services permettaient déjà de « questionner » un document, c’est à dire de l’interroger en langage naturel, afin d’en extraire les points-clés, de le synthétiser ou d’en tirer des définitions de concepts. Imaginez maintenant que vous puissiez interroger ainsi non pas un document unique mais un corpus de documents. Par exemple tous les articles que vous conservez dans :
- Readitlater,
- Pocket,
- Notion,
- Obsidian,
- Logseq,
- etc
Mais aussi et surtout :
- les documents présents dans un dossier Windows/Mac, personnel ou partagé,
- l’ensemble de vos bibliothèques Windows/Mac,
- les échanges d’une discussion sur Slack, Yammer, Whaller, Jamespot, Curebot,…
- les contenus collectés de telle date à telle date par votre plateforme de veille ou votre agrégateur de flux RSS,
- les documents remontés lors une requête dans un moteur intranet, une GED ou un SAE.
Pour se donner une idée du principe, c’est à peu près ce que permet de faire le service Talk to Books proposé par Google, mais appliqué à vos propres documents et c’est la promesse d’une nouvelle génération de services utilisant les grands modèles de langage pour exploiter les documents spécifiques en tant que jeux de données. On parle alors de « fine tuning« .
3 services pour exploiter vos documents
BundleIQ :
- ce service vous propose, dans un premier temps d’importer vos documents dans un « bundle » (paquet).
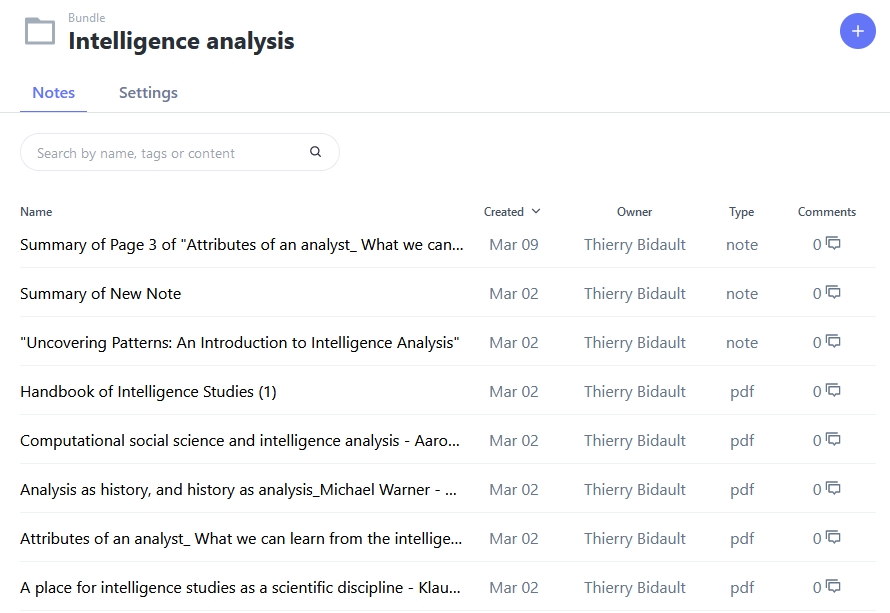
- Une fois cela fait, vous allez pouvoir, à partir de l’espace de travail (workspace), rechercher en langage naturel dans les contenus importés. Le service vous indique alors les passages de votre corpus qui lui apparaissent comme les plus pertinents.
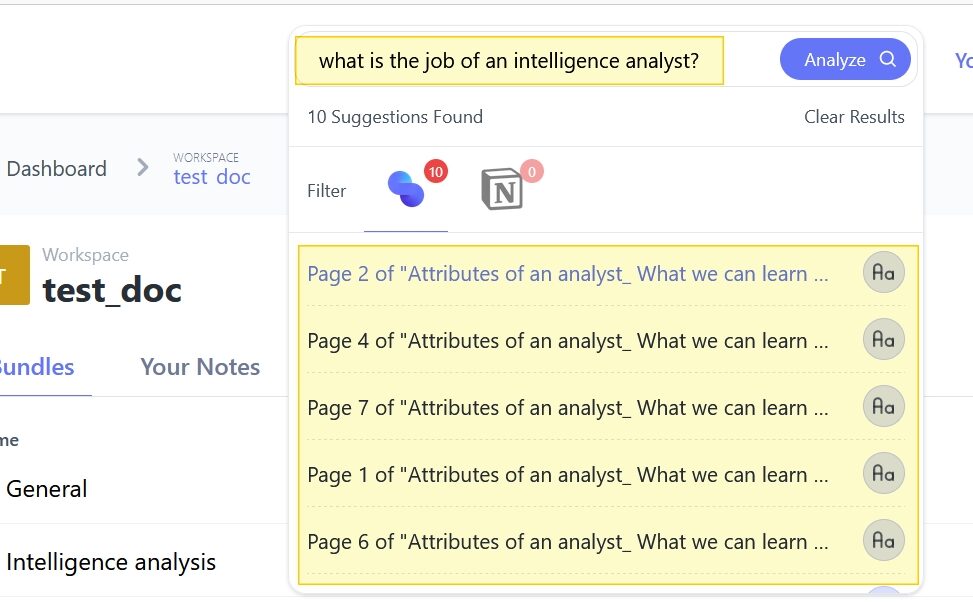
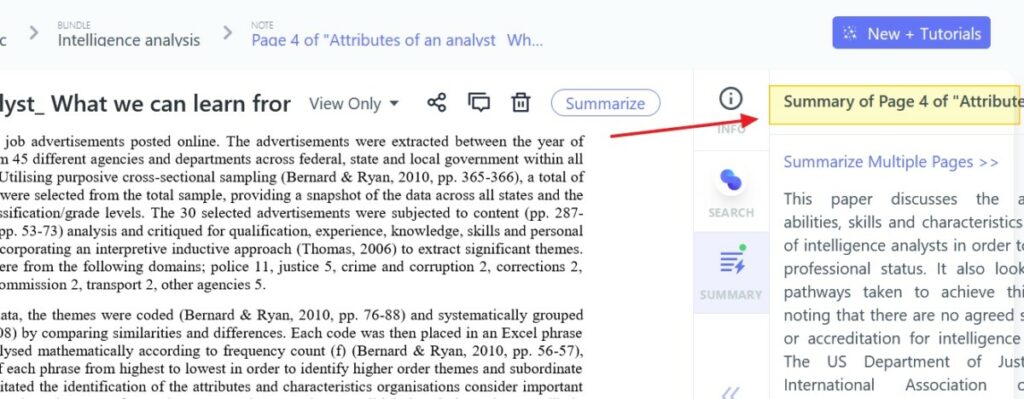
- En cliquant sur un résultat, vous ouvrez le document en question au passage concerné. A partir de là vous pouvez générer un résumé automatique de la page et la sauvegarder comme une note qui viendra s’ajouter à votre bundle.
- BundleIQ s’intégre déjà avec Notion et Twitter.
- Il permet d’alimenter et exploiter un bundle à plusieurs
- Prix : 100$/an
Cody :
- Ce service est probablement le plus simple à comprendre et utiliser des trois présentés ici. Après lui avoir fait « ingurgiter » un ensemble de documents (PDF, .doc, .ppt, html), vous allez créer des conversations pour exploiter ce corpus sur le modèle de l’interrogation de ChatGPT.
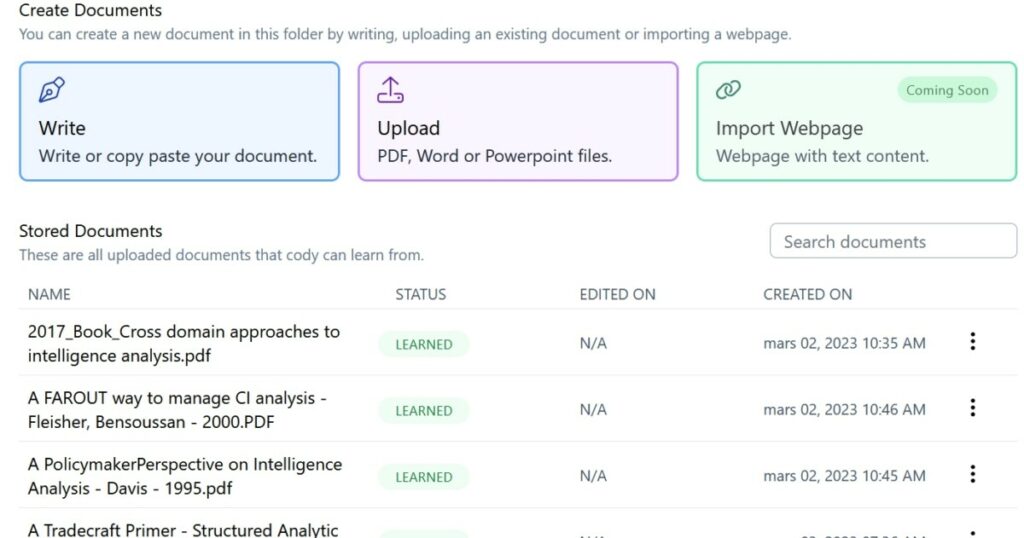
- Lorsque vous lui posez une question, Cody va tenter d’y répondre en utilisant les éléments qui lui semblent pertinents dans les documents fournis. Ainsi, à ma question « Quelles sont les qualités d’un analyste du renseignement? », il crée une réponse en utilisant les contenus de deux documents.

- Autre détail intéressant, le corpus que j’ai chargé est en anglais mais j’ai posé ma question en français. Comme on le constate, il a répondu dans la même langue, ce qui signifie que l’on peut exploiter des documents dans une autre langue sans même avoir à les traduire, le service effectuant ces deux opérations (à l’instar de ChatGPT).
- Cody propose un mode collaboratif.
- Prix : 49$/mois
- L’approche d’Omnilab est particulièrement intéressante. Le service, pour l’instant en bêta, permet de charger un corpus documentaire dans de très nombreux formats :
- docx
- markdown
- epub
- html
- …
- Une fois les documents indexés et l’extension Chrome chargée une fenêtre affiche des suggestions potentiellement intéressantes provenant de votre « library » ou d’autres déjà existantes dans le système. En effet, il est possible de rendre une « library » publique.
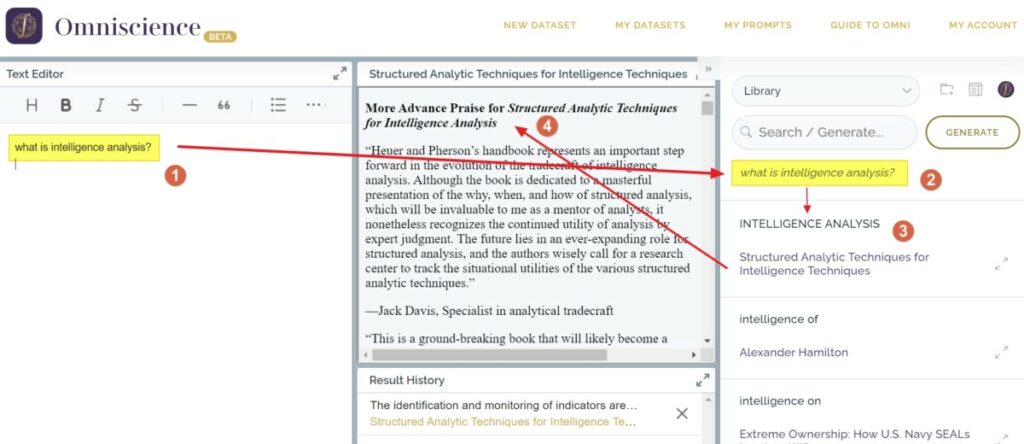
- Omniscience est conçu comme un service d’aide à la rédaction. Il est donc disponible en tant qu’addon dans Google docs mais propose aussi, via l’extension, son propre éditeur de texte. Dans l’un ou l’autre cas, vous disposez d’un outil vous permettant d’exploiter votre documentation en temps réel lorsque vous écrivez. Le service propose de la génération automatique de texte via le bouton Generate.
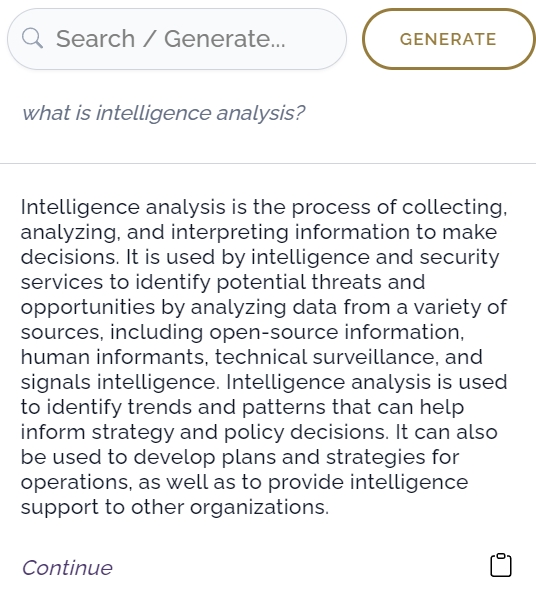
- Omniscience est très intéressant en ce sens qu’il a propose un espace mixte d’aide à la rédaction et à l’exploitation documentaire. A suivre de très près.
- Pour l’instant l’outil n’est pas collaboratif.
- Prix : gratuit durant la phase bêta
Nous avons repéré d’autres services du même type comme Filechat, getChunky, CustomGPT ou Chatbase qui ressemblent à Cody. Ou IngestAI, qui permet de créer de bots de réponse pour Slack, Telegram, Discord et Whatsapp.
Que nous permettent de voir émerger ces services?
Aucun de ces services n’est totalement abouti et l’on comprend en les testant qu’ils sont en train de rechercher leur modèle qui, n’en doutons pas, émergera bientôt, ici ou ailleurs. Ce qui est sûr c’est qu’il faut s’habituer à ces outils qui, pour les professionnels de l’information, joueront le rôle d’assistant. Au fil de nos lectures et rédaction de documents, ils nous conseilleront des contenus issus non plus du web, mais des espaces documentaires qui font sens pour nous et bien sûr, plus nous les utiliserons et mieux ils seront à même de comprendre le contexte informationnel dans lequel nous évoluons.
Étant donné la croissance constante du nombre d’informations et de documents la transportant, il est évident que ces services vont rapidement s’avérer incontournables. Ils sont je pense la brique qui faisait défaut dans un contexte de surinformation perpétuelle. Ils ne se substitueront toutefois pas à une orientation des besoins bien comprise.

Un GPT paramétré et entraîné écrira bientôt comme soi-même. Stephen Wolfram, le créateur du moteur Wolfram Alpha estime qu’en ce qui concerne la réponse aux emails reçus, c’est pour bientôt : https://www.youtube.com/live/flXrLGPY3SU (voir à la toute fin de la vidéo)
Merci Emmanuel,
Les articles qu’il a écrit à ce sujet sont également très éclairants. Il sait de quoi il parle…