Comme vous l’avez constaté dans les articles précédents, la mise en place d’une veille « Quick & Dirty » a pour objectif de récupérer des sources thématiques rapidement. Cela va à l’inverse de la méthodologie classique de sourcing où chaque source doit être évaluée / qualifiée afin de répondre au mieux aux besoins informationnels détectés en interne. Cette méthode se rapproche pourtant beaucoup de celle proposée par les éditeurs de plateformes de veille proposant des bouquets de sources thématiques sur lesquelles vous allez ensuite poser des requêtes par mots-clés. Bien entendu c’est cette dernière opération que nous allons détailler et mettre en œuvre dans cet article, avec pour objectif de ne faire remonter que les informations pertinentes des nombreuses sources mises sous surveillance.
Il nous faut pour cela disposer d’un agrégateur capable de mettre en place du filtrage avancé par mots-clés. Inoreader, dans sa version Pro, est évidemment notre choix principal tant il propose des fonctionnalités de premier plan, notamment grâce à l’usage des règles que j’avais déjà détaillé dans un précédent billet de juin 2015. Billet que je réactualise donc ci-dessous.
Les règles sont l’une des fonctionnalités les plus puissantes d’Inoreader. Elles permettent, dans un premier temps, de filtrer des flux, des dossiers de flux ou même l’ensemble de son compte. Dans un second temps, si le mot-clé défini est détecté par le système, elles permettront de générer des actions que nous préciserons ci-dessous.
Création des règles
Pour accéder à la création de règles rendez-vous dans Automatisation / Règles / Créer une règle.
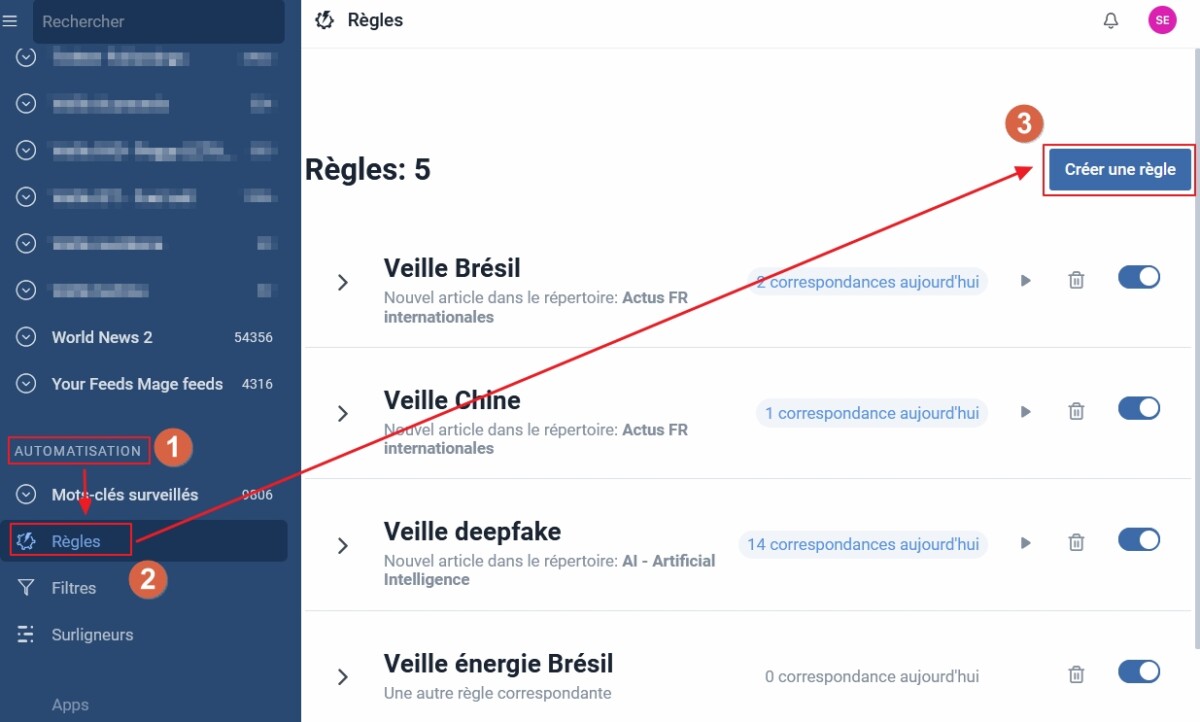
Pour cet exemple je décide de filtrer le dossier « Machine learning », créé précédemment en collectant des flux RSS par scraping des résultats Bing, pour ne faire remonter que les articles traitant de vidéos, images, voix, données et textes synthétiques (si le sujet vous intéresse voir mon dossier « Les technologies du faux : un état des lieux » en HTML ou en PDF).
Choix du périmètre à surveiller
- Je donne un nom à ma règle : » Règle Technos du faux »
- Je choisis les périmètres à filtrer : ici le répertoire (dossier) nommé « Machine Learning (Scraping Bing) » qui comporte une soixantaine de flux.
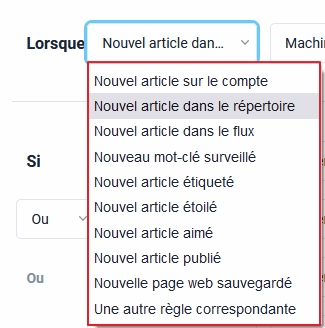
Choix des conditions de filtrage
- Choisir les éléments de filtrage que vous allez privilégier. A savoir « Si » :
- Titre (de l’item)
- Contenu de l’item (soit le texte d’un article)
- Titre ou contenu
- Auteur (attention, il faut être sûr que ce champ sera renseigné par l’émetteur du flux)
- URL du flux : permet de filtrer les items provenant d’un flux grâce à l’URL de celui-ci
- URL sans domaine : permet de rechercher par mots-clés dans les URLS des items sans tenir compte du nom de domaine (v. l’explication sur le blog d’Inoreader)
- Contient des pièces jointes (pour filtrer les podcasts par exemple)
- Contient des images
- Contient une vidéo. Notez que lorsqu’un de ces 3 derniers choix est effectué, le champ « Contient » disparaît puisque l’on utilise plus de mots-clés pour créer un filtre
- Ne contient pas d’image
- Ne contient pas de vidéos
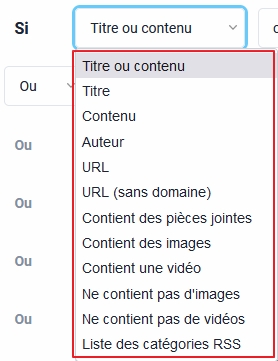 Liste des catégories RSS (soit la catégorie ou tag thématique à laquelle est rattachée un item, article ou post. Attention ce champ est rarement renseigné).
Liste des catégories RSS (soit la catégorie ou tag thématique à laquelle est rattachée un item, article ou post. Attention ce champ est rarement renseigné).
- Ces critères sont cumulatifs et il vous faut choisir si vous souhaitez rechercher des articles correspondants à tous les mots-clés indiqués (ET) ou à l’un ou l’autre des mots-clés indiqués (OU). Notez aussi que lorsque vous ajoutez une expression comme « synthetic data » il n’est pas nécessaire de mettre les guillemets dans Inoreader qui les ajoute automatiquement dès lors que l’expression est inscrite dans une case à gauche.
-
Utilisez le menu déroulant du champ « Contient » pour préciser l’étendue des mots-clés que vous ajouterez dans le champ suivant :
-
Contient / Ne contient pas : possibilité d’ajouter un mot précis ou une expression
-
Est / N’est pas, par rapport à « Contient/Ne contient pas » : le premier retrouve l’expression exacte, par exemple :
« Est = Data » ne retrouve pas « Data analysis » alors que « contient = Data » le retrouve. -
Commence par/Se termine par : attention, il ne s’agit pas de troncatures mais de la possibilité de filtrer les articles dont le titre et/ou le contenu commencent ou se terminent par un mot spécifique. Par exemple tous les articles dont le titre commence par « Ukraine ». La troncature existe par défaut dans Inoreader, c’est à dire que si vous choisissez : Titre/contient/Ukrain vous obtiendrez tous les articles où les mots « Ukraine », « ukrainien », « ukrainiens », « ukrainiennes »,… sont cités dans le titre. Si vous souhaitez uniquement les titres où seul le mot « Ukraine » est cité alors il suffit de cocher la case « Mots entiers uniquement »

-
Correspond/Ne correspond pas à l’expression régulière : il est possible d’utiliser les expressions régulières, c’est à dire un ensemble de conventions syntaxiques reconnues par plusieurs langages de programmation, pour filtrer les flux Inoreader. C’est assez complexe à manipuler mais extrêmement puissant. Voici quelques expressions régulières simples à utiliser :
-
Prendre en compte la casse : « /Total/ » (sans les guillemets) permet de trouver « Total » et pas « total »
- Troncature : « /\bchauss » (sans les guillemets) fera remonter tous les mots commençant par « chauss » (mais pas ceux commençant par « Chauss » car les REGEX sont sensibles à la casse.
- Joker : /Samsung S./ fera remonter les articles évoquant les modèles Samsung S6, S7, S8, …
Serge Courrier a détaillé d’autres usages des REGEX dans un excellent document de 2016 toujours opérationnel.
-
-
Choix des actions mises en œuvre si les conditions sont remplies
- Les items correspondant à vos conditions de filtrage (articles, billets, posts,…) seront :
- Marqués comme lus
- Taggés via une étiquette (Attribuer une étiquette). Ce choix créera dans la partir « Bibliotèque » une sorte de dossier dynamique qui récoltera au fil de l’eau tous les items répondant aux conditions mises en œuvre. C’est à mon sens l’une des possibilités les plus riches car permettant ensuite des actions complémentaires comme la diffusion automatisée de digests (newsletters automatiques).
- Etoilés, c’est à dire envoyés dans le dossier « Lire plus tard »
- Publiés : redirigés vers votre profil public Inoreader ou vers un groupe.
- Rediriger sur email : permet par exemple l’envoi automatique d’un lien à un collègue
- Afficher une alerte sur le bureau: Attention ceci ne fonctionne que si Inoreader est ouvert dans votre navigateur.
- Rediriger vers des services de stockage/lecture différée (à condition d’avoir lié au préalable ces services à votre compte Inoreader) :
- Instapaper
- Evernote
- Onenote
- Dropbox
- Google Drive
- Pousser les notifications vers mobile : envoi d’un SMS d’alerte au numéro indiqué
- Déclencheur webhook.
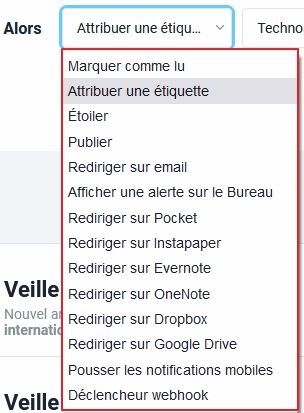
Pour cette exemple nous avons choisi comme unique action (car on peut en cumuler plusieurs) d’envoyer les articles correspondants vers une étiquette (choix 2 ci-dessus).
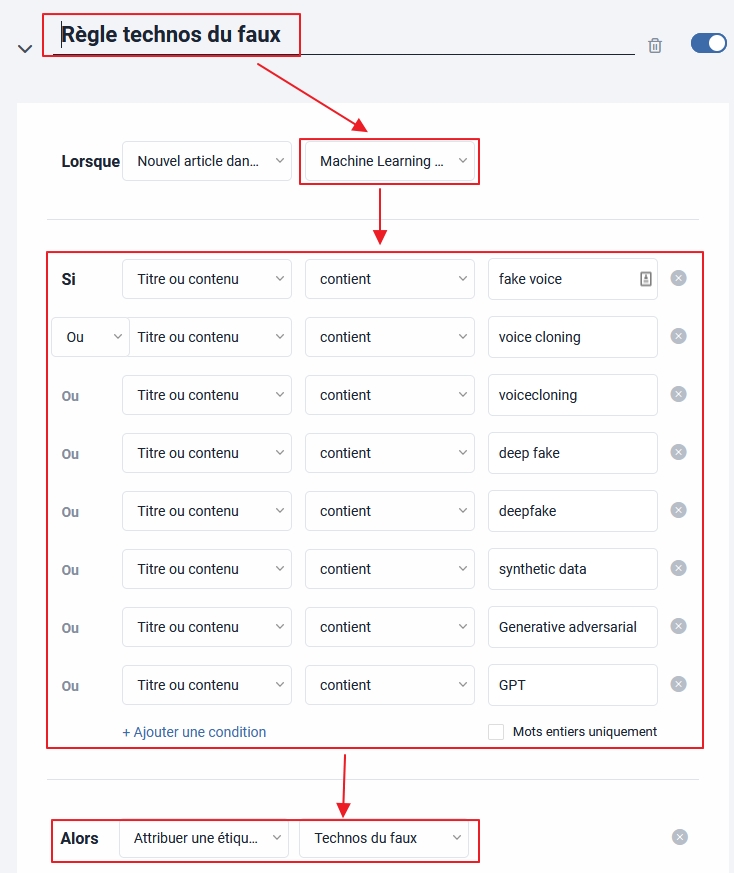
Voici le résultat de ce filtrage par mots-clés :
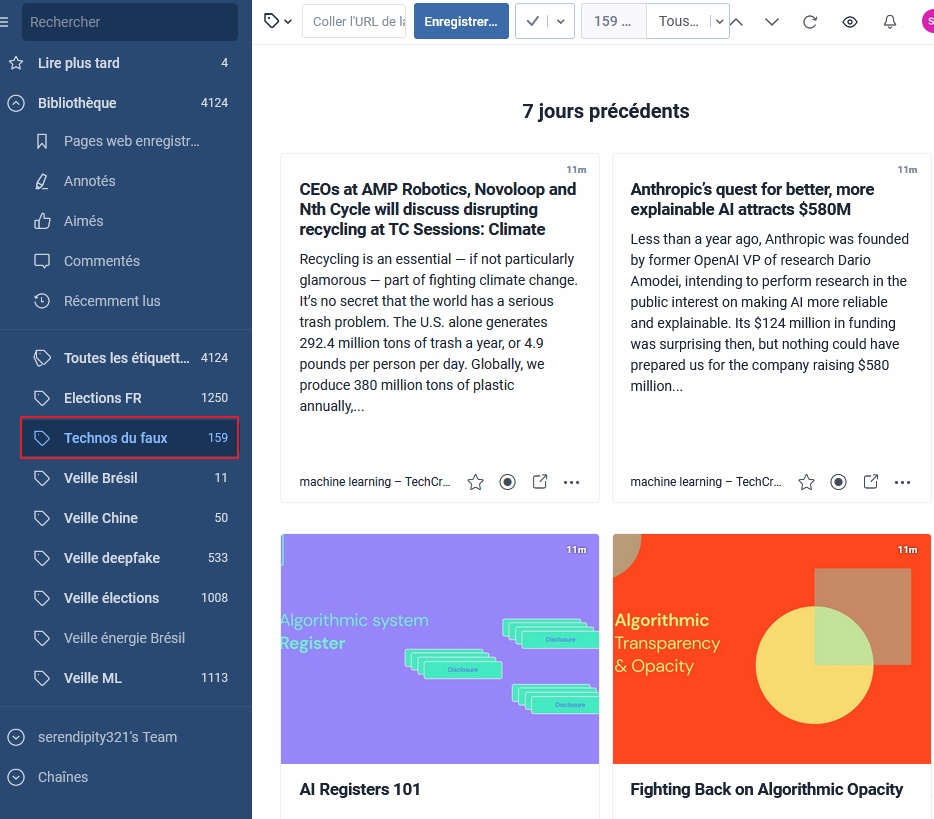
C’est donc en travaillant de manière précise sur le vocabulaire de la thématique à suivre (champ sémantique –> mots-clés) que l’on parvient à transformer un sourcing « Quick & dirty » en un résultat « propre ».
Dans le prochain article nous verrons comment mettre en place un filtrage un peu moins précis mais nanmoins intéressant avec un agrégateur gratuit et plus simple qu’Inoreader.
Photo by Jess Zoerb on Unsplash

