Dans le dernier article nous avons vu qu’Inoreader pouvait être un bon outil de sourcing rapide grâce aux bundles qu’on peut lui ajouter d’un clic. Nous continuons dans le quatrième article de cette série avec de la collecte de sources « en masse ». Notre objectif étant de récolter le plus de sources d’information potentiellement utiles en un temps limité nous déclinons l’éventail des outils et techniques le permettant même si toutes ne seront pas forcément utilisées.
Les annuaires de Feedspot et Feedly
Deux autres agrégateurs connus, Feedspot et Feedly proposent des annuaires de flux particulièrement bien fournis. Le premier annonce 250000 flux et le second ne donne pas de chiffres mais en propose probablement autant. Nous allons donc voir dans cet article comment exploiter ces listes de flux RSS. Ce sera un peu plus technique que dans les précédents articles mais l’on parle ici de 15 minutes maximum pour récupérer des listes de flux thématiques déjà constituées et incluant souvent entre 50 et 200 flux qualifiés.
L’annuaire de Feedspot est accessible ici. Il est subdivisé en neuf catégories thématiques :
- Top categories
- Browse by locations
- Popular Blog lists
- Popular podcasts lists
- Popular forum lists
- Popular magazine lists
- News websites by country
- Recent blog lists
- Recent podcast lists
Chaque catégorie est elle-même divisée en d’innombrables sous-catégories. Voici par exemple la sous-catégorie « Top 100 World News RSS Feeds » rattachée à la catégorie « News websites by country ».
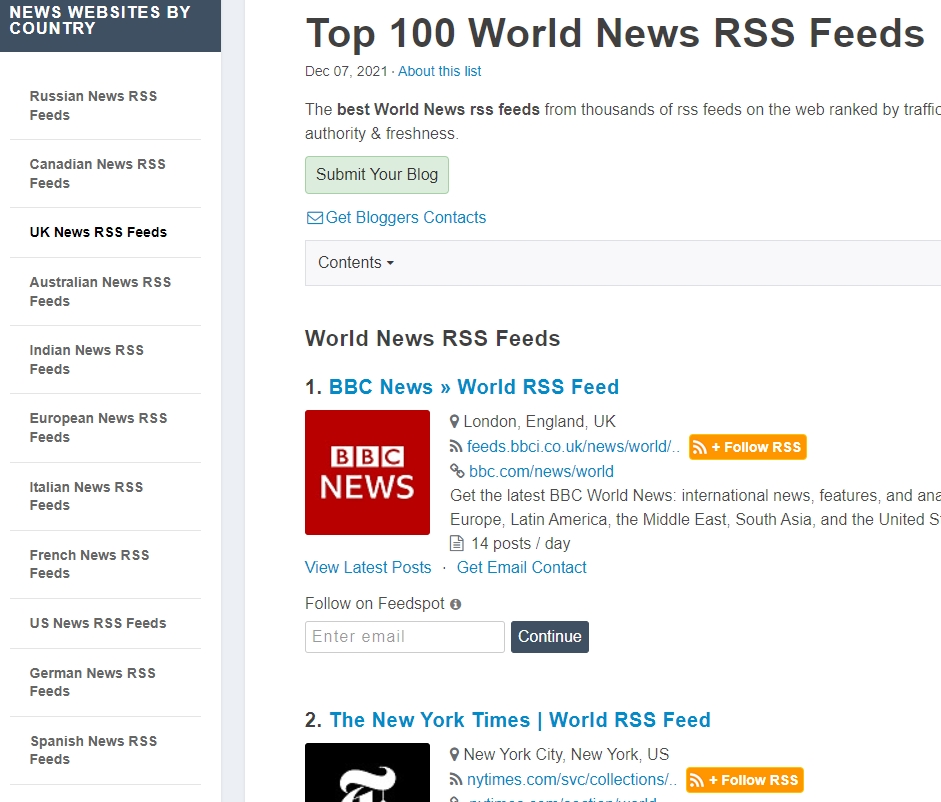
L’annuaire dispose d’un moteur de recherche qui permet de trouver facilement les catégories existantes (en haut à droite).
L’annuaire de Feedly possède quant à lui deux entrées :
De fait il s’agit plutôt d’un ensemble de listes de flux regroupées par thèmes mais non classé par catégories et sous-catégories. Par ailleurs, il ne dispose pas d’un moteur de recherche. Il faudra donc utiliser l’opérateur « site: » de Google pour l’explorer. Par exemple :
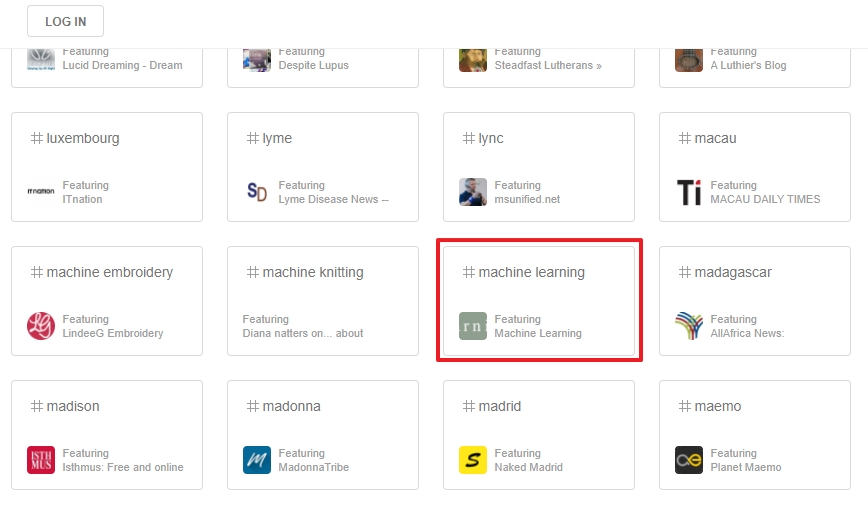
site:https://feedly.com/i/all "machine learning"
Google donne ici un seul résultat qui est la page 11 de l’annuaire Feedly dans laquelle se trouve bien la catégorie « Machien learning » :
Feedspot. Cas 1 : les bouquets de flux « ouverts »
Dans son annuaire Feedspot propose soit :
- des flux RSS dont l’URL est récupérable directement par copier-coller et que l’on peut donc ajouter facilement à son agrégateur de flux
- des flux RSS dont l’URL est encodée et qui nécessiteront un traitement supplémentaire
Nous allons donc rencontrer deux cas à traiter différemment. Par ailleurs pour collecter en masse les flux RSS d’une page (car notre objectif n’est pas de collecter les flux un par un) nous aurons besoin d’un outil de scraping c’est à dire d’un outil qui permet d’extraire des contenus structurés d’une page web. D’après mes tests le plus facile à utiliser est Instant Data Scraper, une extension gratuite pour le navigateur Chrome. Une fois installée, rendez-vous sur une page thématique de Feedspot, par exemple celle des Top 100 World News RSS Feeds évoquée plus haut. Puis :
- Cliquez sur le bouton d’Instant Data Scraper

- L’extension sélectionne une partie de la page qu’il met en fluo.
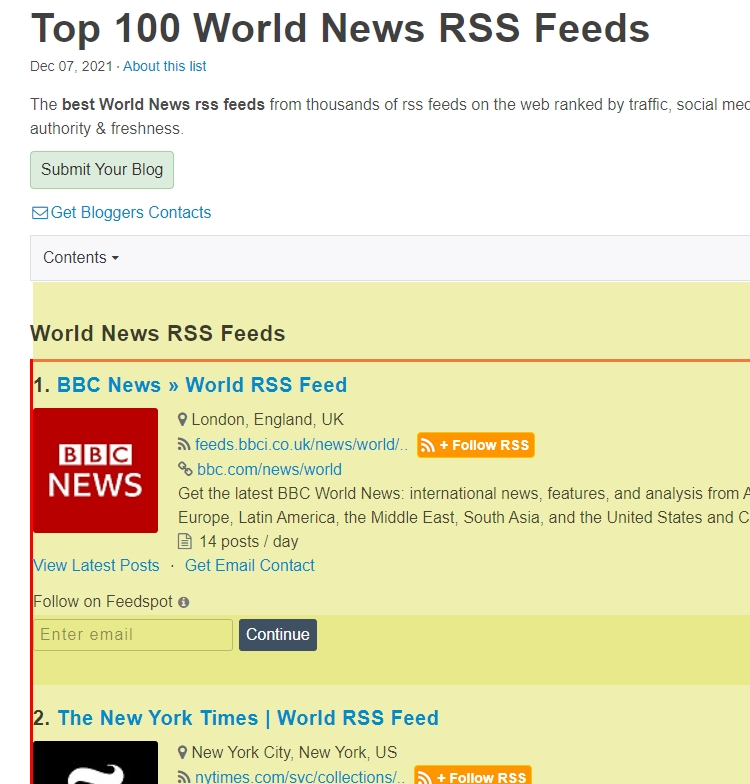
- Il structure le contenu de la partie sélectionnée dans un tableau. Repérez la colonne qui liste les flux RSS, ici « trow href » et supprimez les autres en cliquant sur la petite croix noire en haut à droite de chaque colonne.
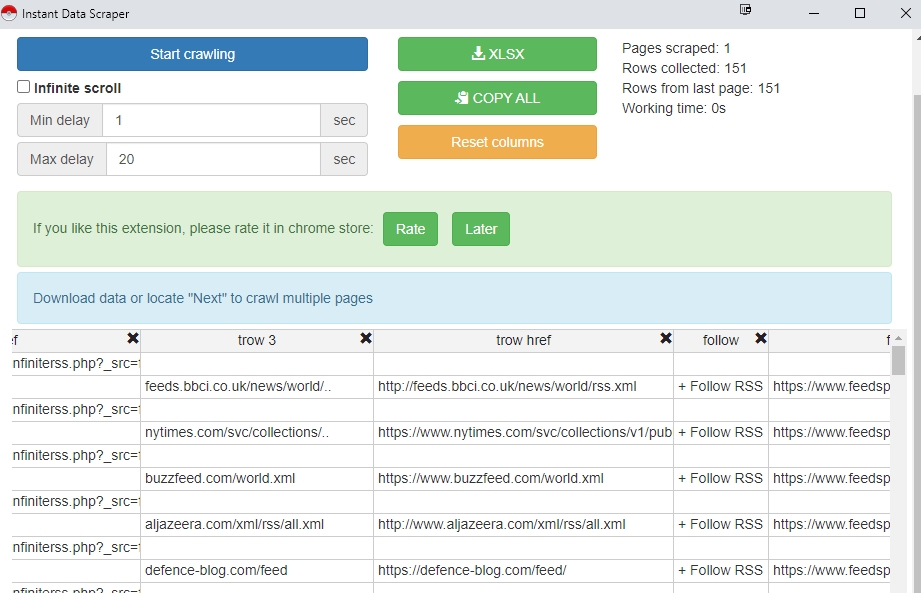
- Cliquez sur le bouton vert Copy All pour copier tous les liens présents dans la colonne « trow href »
- Collez ces flux dans OPML Generator et cliquez sur « Generate »
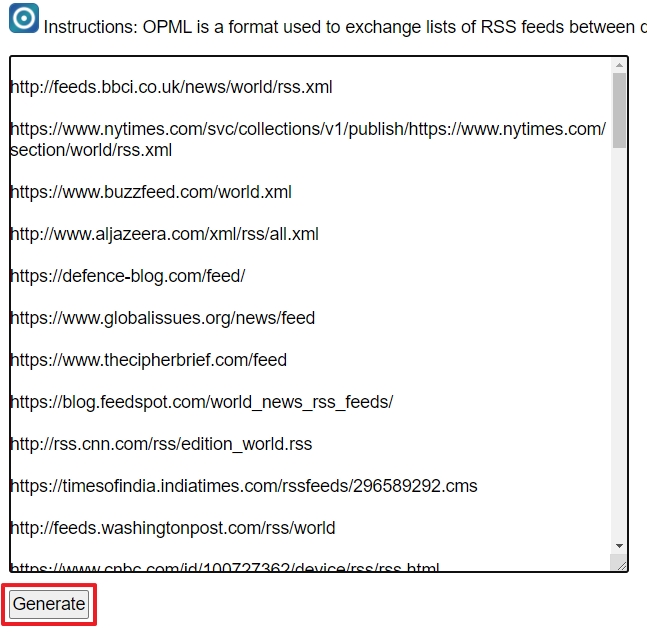
- Enregistrez le fichier OPML généré sur votre disque dur
- Intégrez-le dans Inoreader (cf. le premier article)
Feedspot. Cas 2 : les bouquets de flux « fermés »
Certaines listes comportent des flux encodés. C’est le cas par exemple de celle-ci.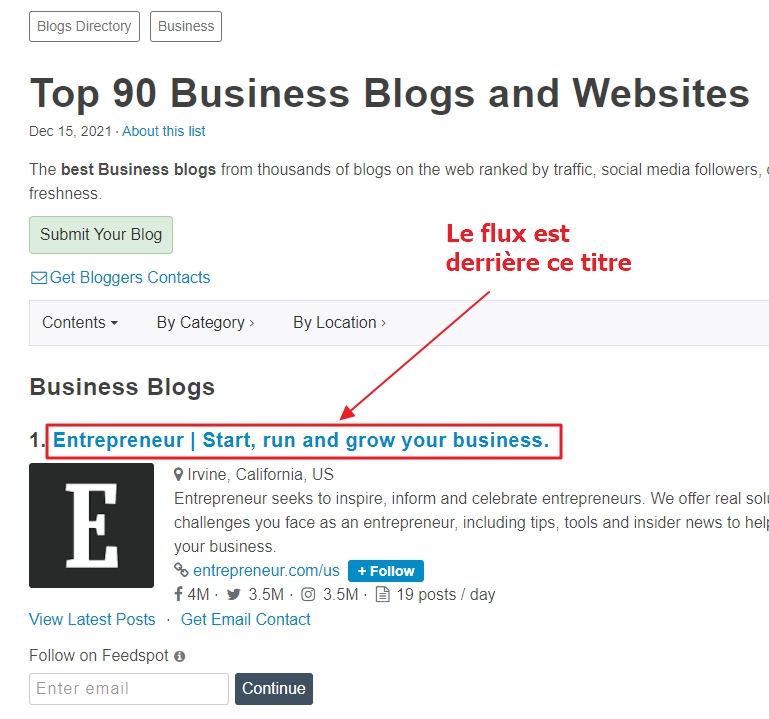
A la différence de la page précédente, le flux RSS n’est pas immédiatement accessible mais caché derrière le titre de chaque site visible. Si on fait un clic-droit « Copier le lien » (Firefox) ou « Copier l’adresse du lien » (Chrome) voici l’adresse que l’on obtient :
https://www.feedspot.com/infiniterss.php?_src=feed_title&followfeedid=4425104&q=site:https%3A%2F%2Fwww.entrepreneur.com%2Flatest.rss
Comme on le voit, le flux est positionné à la fin et encodé. Il faut donc réussir rapidement à ne conserver que la partie en rouge du lien et à la ré-encoder en une URL de flux exploitable qui ressemblera à çà:
https//www.entrepreneur.com/latest.rss
N’ayant pas les compétences nécessaires pour cela je me suis tourné vers Nicolas Duquesne, développeur spécialisé Excel, Google Sheets, Calc et qui se présente modestement comme un développeur qui « transforme des tableurs en trucs sympa Excel et Calc ». Indubitablement la bonne personne pour m’aider 🙂 . La suite de ce tuto ainsi que la solution qu’il propose via Excel et Google Sheets sont donc les siennes et je l’en remercie grandement.
L’extension Instant Data Scraper propose les résultats de scrap (parcours d’un document HTML) dans un tableau. La colonne qui nous intéresse est celle des liens « tlink href ». 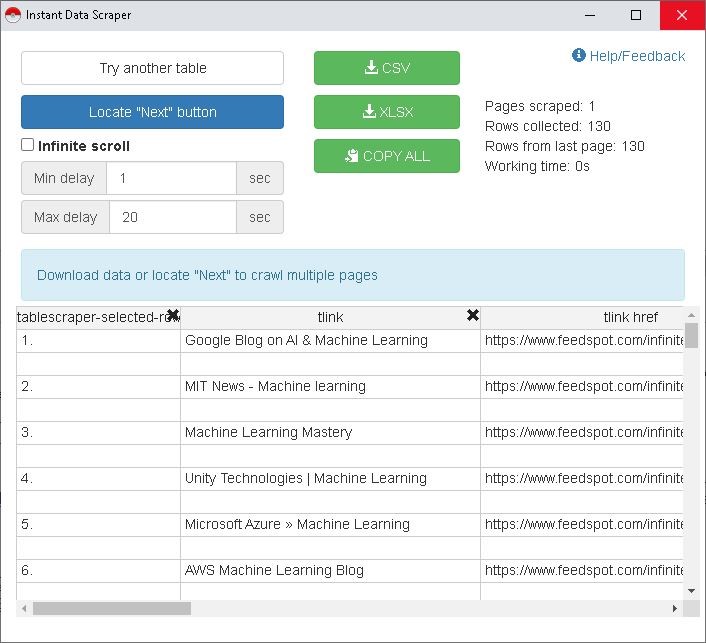
Il suffit de supprimer les colonnes de la sélection en cliquant sur la croix noire de chaque colonne.
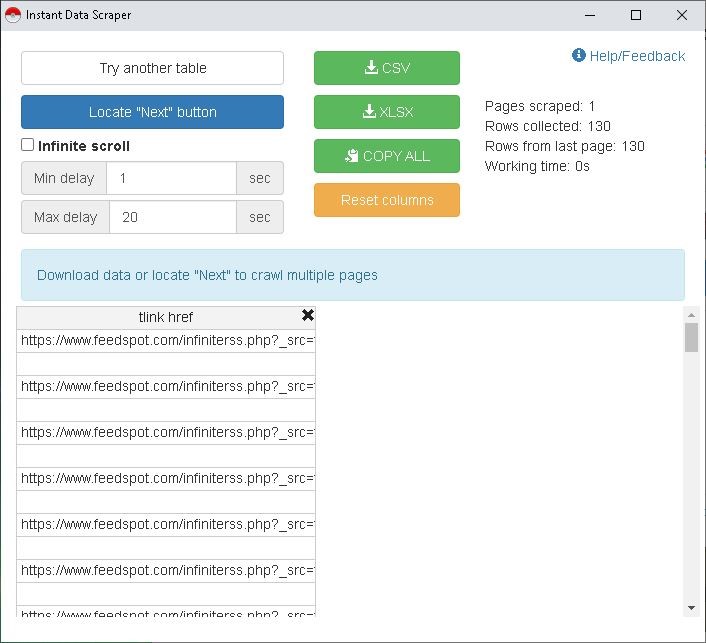
Les liens comprennent une partie concernant directement les flux et restent codés en %. Le générateur OPML ne supportant pas les liens codés en % nous allons devoir décoder les liens avec un service spécifique : URL-encode-decode.com .
Depuis Instant Data Scraper il faut cliquer sur « Copy all », puis coller la liste dans la zone de texte prévue pour l’entrée.
Lancez l’opération « Decode url »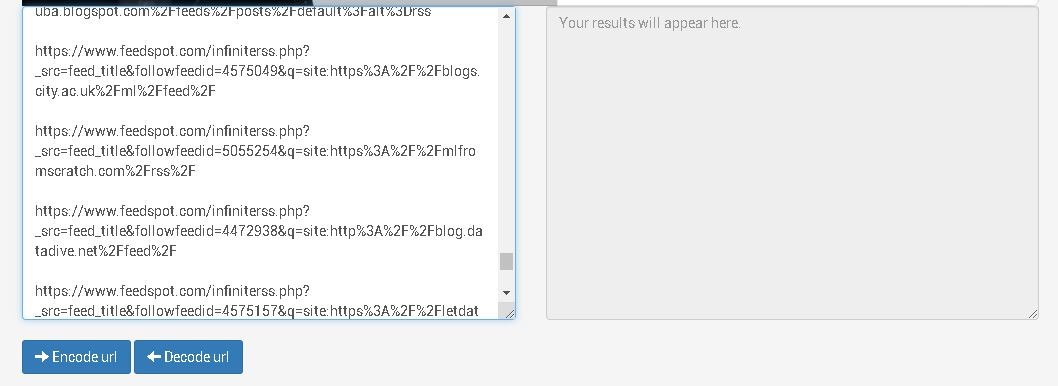
Le résultat apparaît à droite :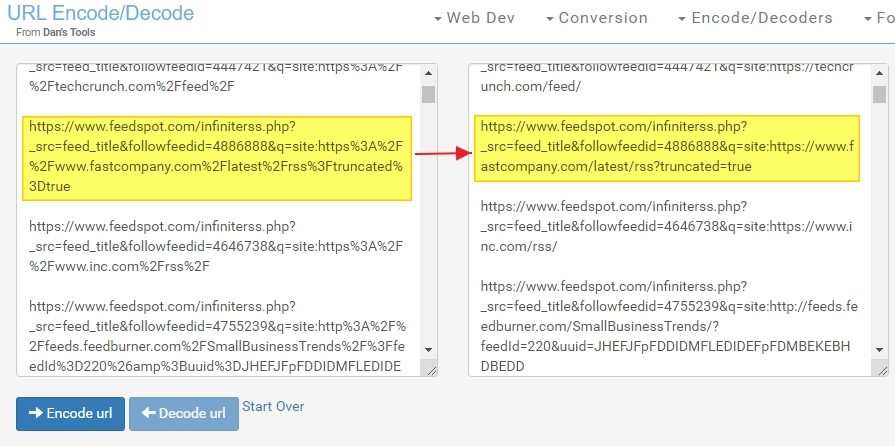
- Coupez le contenu de la colonne de droite.
- Appuyez sur « Start over » pour réinitialiser la procédure.
- Collez une seconde fois le contenu découpé dans la colonne de droite, puis appuyez encore sur « Decode url ». Cette double opération permet de se prémunir contre des encodage doubles en %.
- Copiez le contenu de la colonne de droite
Seconde opération, il faut maintenant extraire l’URL du flux RSS (en jaune) et supprimer la partie qui la précède (en bleu). https://www.feedspot.com/infiniterss.php?_src=feed_title&followfeedid=4425104&q=site:https://www.entrepreneur.com/latest.rss
Pour cela vous pouvez utiliser soit Excel (local ou en ligne) soit Google Sheets.
Avec Google Sheets :
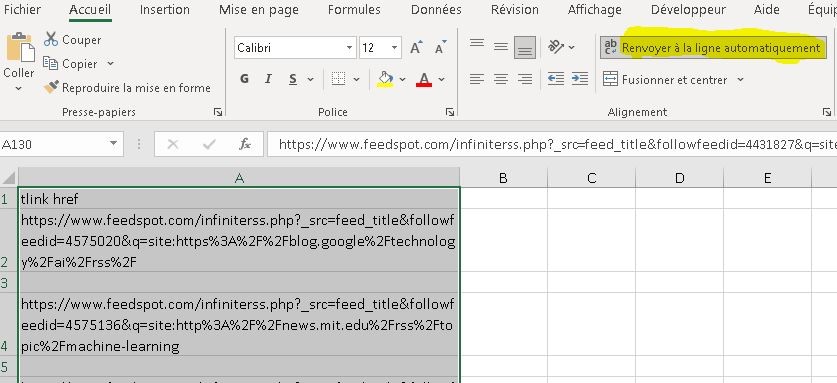
Collez le résultat du décodage dans la première colonne, puis demandez une mise à la ligne automatique (surlignage jaune). 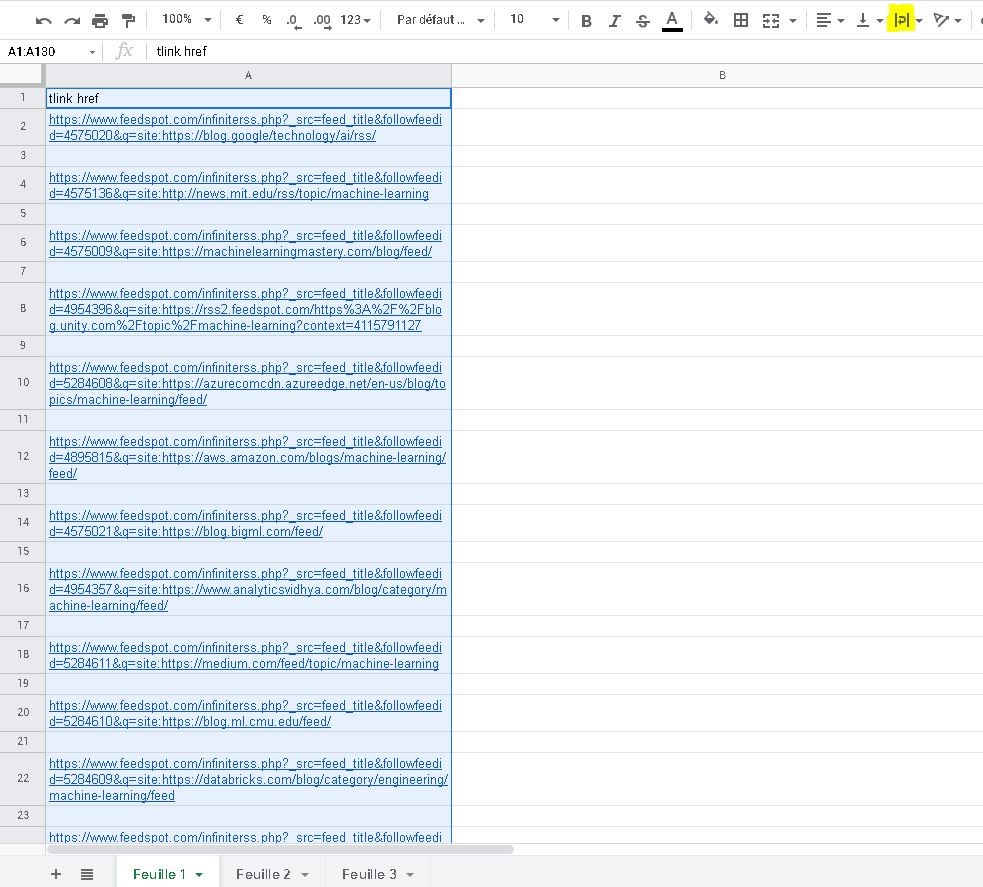
Des lignes vides subsistent et vont nous gêner pour les opérations à venir. Nous allons procéder à un tri sur place pour n’avoir que les lignes pleine en haut :
- Cliquez sur l’onglet « Données »,
- Puis créer un filtre.
- L’en-tête « tlink href » dispose d’une flèche vers le bas à sa droite.
- Il suffit de cliquer sur cette flèche et sélectionner un tri de A à Z.
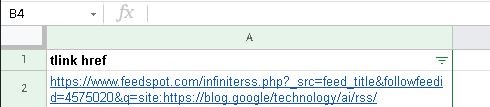
- Entrez la formule suivante dans la cellule B2, adjacente à A2 :
=DROITE(A2;NBCAR(A2)-(CHERCHE("site:";A2;1)+NBCAR("site:")-1))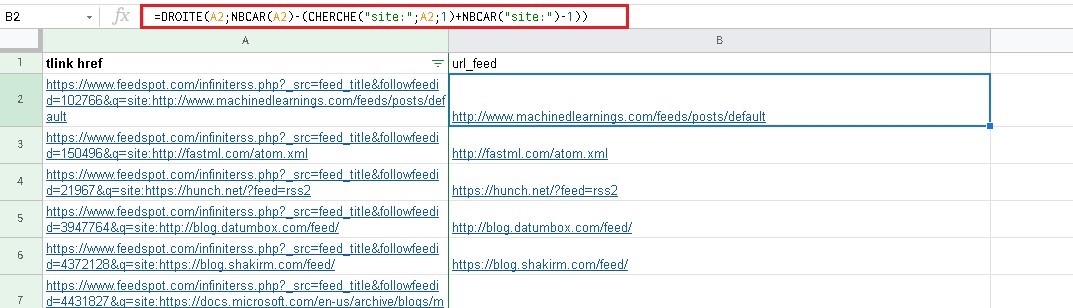
- Copiez B2 jusqu’en bas en « tirant » avec la « main de copie », c’est-à-dire la croix bleu en bas à droite du rectangle bleu encadrant B2.
- Laissez appuyé le bouton gauche de la souris pour la copie.
- Il suffit en suite de copier la colonne traitée (ici la B) (sans l’en-tête) et coller la coller dans le générateur OPLM puis d’importer le fichier OPML dans votre agrégateur.
Avec Excel :
Collez le résultat du décodage dans la première colonne, puis demandez une mise à la ligne automatique (surlignage jaune). Des lignes vides subsistent et vont nous gêner pour les opérations à venir. Nous allons procéder à un tri sur place pour n’avoir que les lignes pleine en haut :
- Sélectionnez la colonne sans l’entête « tlink href »
- Cliquez sur l’onglet « Données »
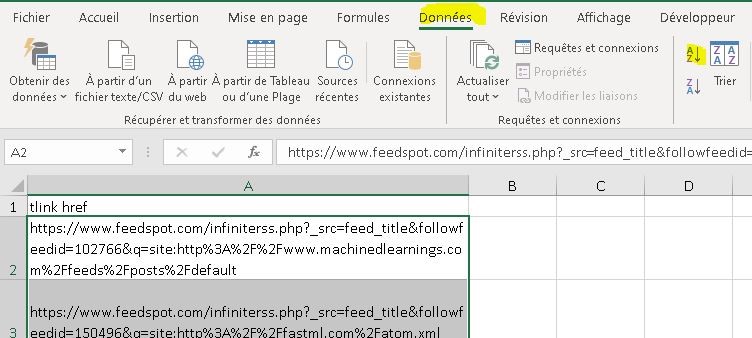
- puis trier la sélection avec le bouton AZ surligné en jaune
- On entre la formule suivante dans la cellule B2, adjacente à A2.
- Puis copiez B2 jusqu’en bas avec la « main de copie » c’est-à-dire la croix bleu en bas à droite du rectangle bleu encadrant B2.
- Il suffit en suite de copier la colonne traitée (ici la B), sans l’entête, et de coller son contenu dans le générateur OPLM puis d’importer le fichier OPML dans votre agrégateur.
Les bouquets de flux « fermés » de Feedly
Les bouquets de flux proposés sur Feedly sont tous encodés, il faudra donc utiliser la même technique que ci-dessus. Seul le scraping est un peu différent ici. En effet, Instant Data Scraper ne parvient pas à récupérer tous les flux d’une page en une seule fois.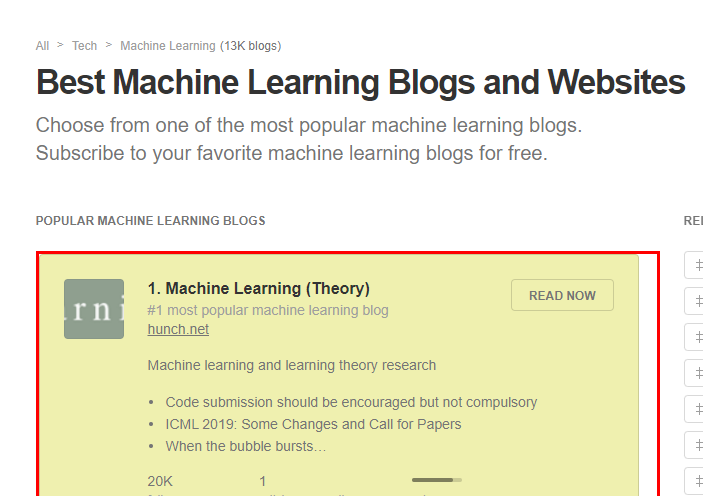
Il faut donc le relancer autant de fois que nécessaire en cliquant sur le bouton bleu Start Crawling et ce jusqu’à ce qu’il ait récupéré tous les liens de la page (ici il y en a cinquante). Autre différence, la colonne à conserver ici se nomme « link href ».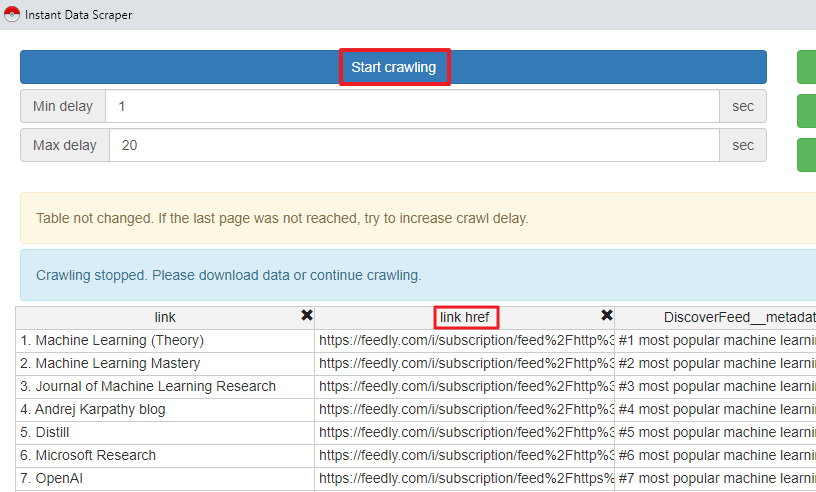
Une fois le contenu de cette colonne récupéré on appliquera les mêmes étapes qu’avec les flux « fermés » de Feedspot :
- Double décodage dans le service URL Encode Decode
- Utilisation d’Excel ou de Google Sheet pour supprimer le début de l’URL
- Copier le contenu de la colonne « traitée »
- Coller son contenu dans le générateur OPML et importer le fichier OPML généré dans votre agrégateur
Voilà comment récupérer en quelques minutes des dizaines de flux RSS qualifiés pour démarrer sa veille.
Rassurez-vous, cet article était le plus « technique » de cette série mais cela vaut le coup de le mettre en oeuvre.

