Searx est un métamoteur mis en avant récemment sur le blog Les outils de la veille (mais que vous aviez peut-être découvert dans mes favoris publics en décembre 2016).
Il se positionne comme un service respectueux de la vie privée et ne personnalise donc pas les résultats ni ne conserve de profil de recherches. En tant que métamoteur il exploite une (infime) partie des résultats de moteurs primaires (Google, Bing) ou secondaires (Gigablast) en n’oubliant pas bien sûr de les dédoublonner avant affichage. Par ailleurs il agit également comme un métamoteur vertical puisqu’il permet de rechercher dans 10 catégories de moteurs différentes :
- Général
- Fichiers
- Images
- Informatique
- Carte
- Musique
- Actualité
- Sciences
- Réseaux sociaux
- Vidéos
Configurer Searx avant de lancer ses recherches
Searx dispose de plusieurs avantages. Tout d’abord on peut configurer de nombreuses fonctionnalités en se rendant dans les préférences en haut à droite.
- Onglet Général : permet de sélectionner
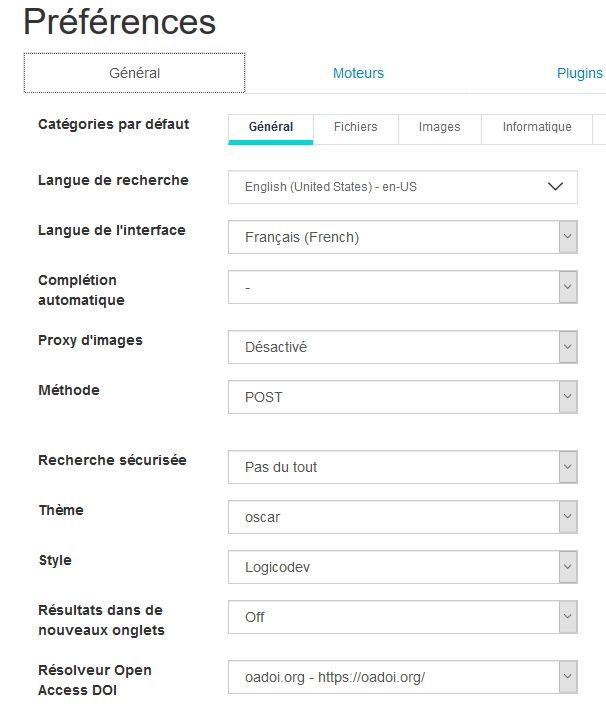
- la catégorie par défaut où on lancera la recherche (web généraliste, fichiers, images,…)
- la langue de recherche (31 proposées)
- la langue de l’interface
- l’autocomplétion pour 6 moteurs/métamoteurs
- l’utilisation d’un proxy pour les résultats images
- le mode d’interrogation en POST ou en GET (POST par défaut)
- le filtrage de contenus offensants
- un thème graphique
- un style
- le lancement des résultats dans de nouveaux onglets
- un résolveur Open Access DOI pour les articles scientifiques
- Onglet Moteur : vous allez pouvoir ici choisir d’activer ou de désactiver des dizaines de moteurs différents pour chacune des catégories. Une transparence particulièrement appréciable donc.
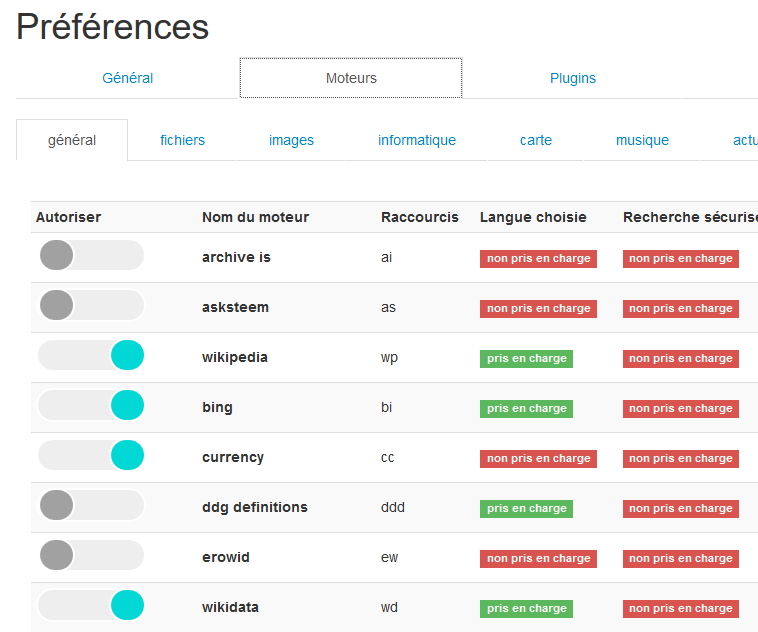 Attention, de nombreux moteurs proposés ne remontent pas forcément que des contenus légaux (torrents, P2P), notamment dans la catégorie « Fichiers »
Attention, de nombreux moteurs proposés ne remontent pas forcément que des contenus légaux (torrents, P2P), notamment dans la catégorie « Fichiers » - Onglet Plugins : 8 fonctionnalités que vous pouvez choisir ou non d’activer
- Utiliser Open Access DOI : permet de … contourner les verrous payants de certaines publications scientifiques (mais c’est pas moi qui le dis hein)
- HTTPS rewrite : permet de forcer le HTTPS sur les résultats en HTTP
- Défilement infini : la page de résultats est infinie (pas besoin de cliquer pour se rendre à la page suivante)
- Ouvrir les liens de résultat dans un nouvel onglet : un doublon avec la même fonctionnalité proposés dans l’onglet général?
- Self Information : vous permet de trouver votre propre adresse IP
- Lancer la recherche lors d’u choix d’une catégorie : lorsqu’on lance une requête elle s’effectue dans la catégorie par défaut. En décochant cette case on peut choisir de la lancer dans plusieurs catégories en même temps, une possibilité qui pourrait s’avérer utile pour la suite…
- Nettoyeur d’URL de suivis : permet d’éviter le tracking à partir d’URLs de redirection
- Raccourcis comme VIM : permet de parcourir les résultats en utilisant les raccourcis clavier
- Onglet Répondant : des infos sur les cookies non-intrusifs qu’il utilise
- Onglet Cookies : noms et valeurs des cookies enregistrés sur le navigateur
Les opérateurs de recherche qui fonctionnent
Les tests ont été effectués sur la catégorie de moteurs « Général ».
La plupart du temps avec les métamoteurs, les opérateurs booléens ou de ciblage sont limités. Voyons ce qui fonctionne ici :
- AND : comme d’habitude avec les moteurs web, il suffit de laisser un espace entre deux mots pour qu’il soit considéré comme un ET logique
- NOT : fonctionne en utilisant le signe « -« , comme sur Google
- OR : fonctionne
- Expression entre guillemets : fonctionne
- Opérateur « intitle: » : fonctionne
- Opérateur « inurl » : fonctionne
- Opérateur « intexte » : fonctionne
- Opérateur « site: » : fonctionne mal (résultats limités issus de Google)
- Opérateur « filetype: » : fonctionne (résultats issus de Google et de Bing)
Il va donc être possible d’effectuer de requêtes un peu évoluées mais attention!! les opérateurs testés ci-dessus ne sont pas reconnus par l’ensemble de moteurs pris en compte par Searx, ce qui veut dire qu’en les utilisant vous allez limiter les résultats aux seuls moteurs qui les reconnaissent, l’intérêt du métamoteur diminuant alors fortement.
Searx permet également de restreindre la recherche avec, à droite de la boîte de recherche :
- un menu déroulant permettant de limiter sa recherche dans le temps
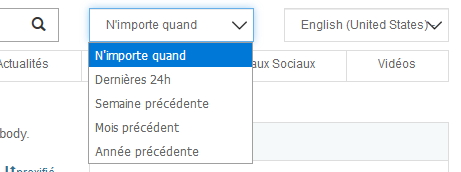
- un menu déroulant permettant de choisir la langue des résultats
Les flux RSS de Searx
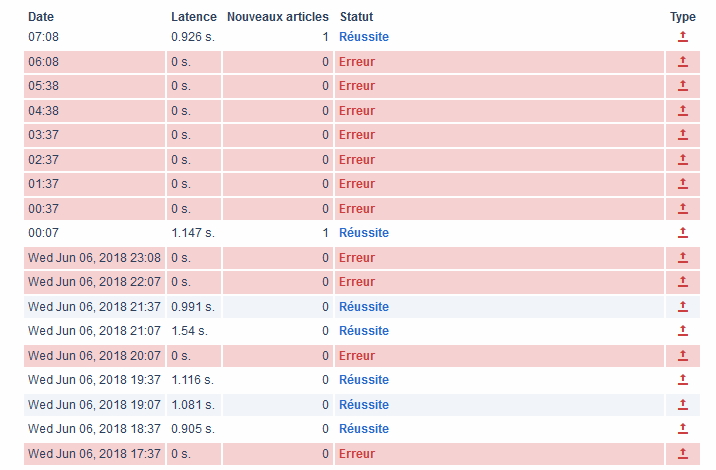
SearX a la bonne idée de produire un flux RSS pour chaque requête effectuée, ce qui permet de surveiller les nouveaux résultats découverts par les robots des moteurs qu’il prend en compte et d’ajouter ainsi des sources à sa veille radar.
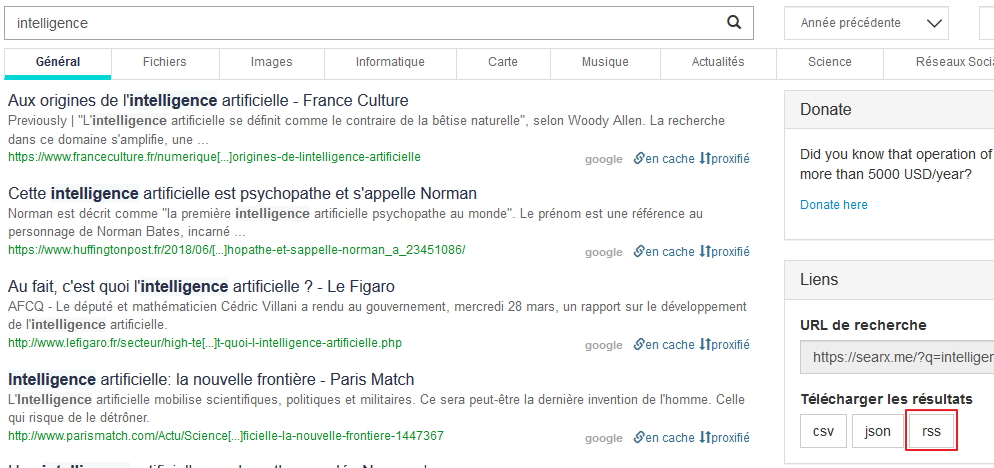
A l’usage cependant tout n’est pas si simple…
En effet, après pas mal de tests force est de constater que tout ne fonctionne pas parfaitement avec ces flux.
Premier problème : pour chaque requête vous trouvez à droite des résultats un bouton « RSS » supposé permettre d’accéder au flux à récupérer. Or, à chaque fois que l’on clique dessus il affiche le message « Rate limit exceeded ». Ce n’est heureusement pas difficile à contourner. Il suffit d’utiliser une extension de détection de flux RSS (Awesome RSS pour Firefox, Extension abonnement RSS pour Chrome) :
- cliquez sur l’icône de l’extension pour obtenir le flux RSS dans la barre d’adresse.
- copiez l’adresse du flux
- collez-le dans Inoreader et cliquez sur « Enter » pour l’ajouter
Second problème : les flux ne fonctionnent que lors d’une interrogation de la catégorie de moteurs « Général ». Pour les autres, alors qu’ils sont reconnus comme tels par Firefox, ils ne sont pas pris en charge par Inoreader, Feeder (Chrome), Netvibes et Feedly. Il doit donc y avoir un problème dans leur configuration technique. Vraiment dommage, il y a là un rendez-vous raté.
Troisième problème : les flux ne se mettent pas à jour à chaque sollicitation de votre agrégateur. Probablement dans le but d’éviter la sursollicitation des serveurs, la mise à jour est épisodique mais ce n’est pas vraiment un problème pour des flux issus d’un métamoteur dont les résultats sont nécessairement moins « frais » que ceux des bases de données des moteurs qu’ils exploitent.
Conclusion
SearX est un métamoteur hautement estimable, tant pour la largeur de sa couverture que pour sa volonté de transparence affichée (et mise en oeuvre). On reste malheureusement sur sa faim quant à l’exploitation des flux RSS qu’il propose. D’autant plus frustré qu’il suffirait probablement de pas grand chose pour qu’ils fonctionnent bien et fasse de ce métamoteur une bonne source de veille.
Bonjour,
Merci pour ce retour.
as-tu essayé de contacter l’équipe de SearX pour la correction des flux RSS ?
Oui mais pas de réponses pour l’instant.