Comme vous l’aurez probablement remarqué, Scoop.it a eu la riche idée de supprimer le flux de ses pages de curation. Bien pratiques, ces flux permettaient d’éviter d’avoir a se créer un compte Scoop.it pour suivre les découvertes des uns et des autres et permettaient surtout de centraliser sa veille dans un agrégateur de flux.
Heureusement il y a toujours des services qui permettent de créer des flux sur des pages HTML qui n’en disposent pas (ou plus).
Test avec Feedity
J’ai d’abord utilisé Feedity que je connais bien et qui propose un mode graphique très simple d’utilisation. J’ai choisi comme exemple (et parce que j’aime les mises en abîme) de surveiller l’incontournable page RSSCircus proposée par Serge Courrier (@secou).
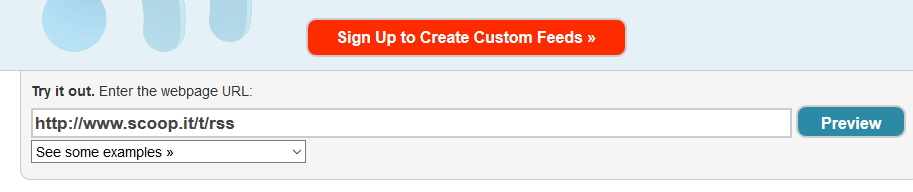
Après avoir indiqué à Feedity son adresse web et cliqué sur « Preview » on accède au fort pratique sélecteur visuel. Il suffit de sélectionner à l’aide de la souris un titre pour que tous soient sélectionnés automatiquement car reconnus comme des éléments similaires par l’outil.
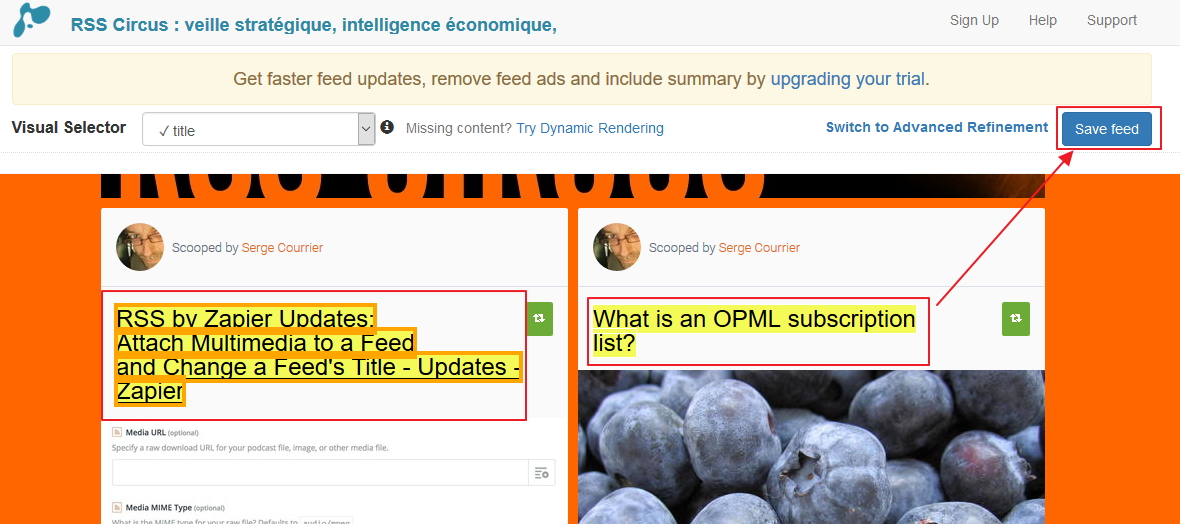
On clique ensuite sur « Save feed » et il n’y a plus qu’à récupérer le flux généré par l’outil.

Franchement ça fonctionne tout seul. Seul problème, Feedity, dans sa version gratuite ne recueille que 5 items (articles, posts, …) par jour. Suffisant pour une page Scoop.it pas trop alimentée mais vite limité pour suivre les plus riches.
Pour info les offres de Feedity sont ici.
Test avec Fivefilters
Fivefilters est un peu plus complexe mais permet de créer des flux non limités gratuitement.
Dans le formulaire il faut d’abord indiquer l’URL de la page Scoop.it à surveiller.
Il faut ensuite trouver une variable qui permette à l’outil de repérer les URL à récupérer dans la page et à injecter dans le flux RSS à créer. En jetant un coup d’oeil au code d’une page Scoop.it et après tests, il est possible d’utiliser les variables h2 postTitleView ou title
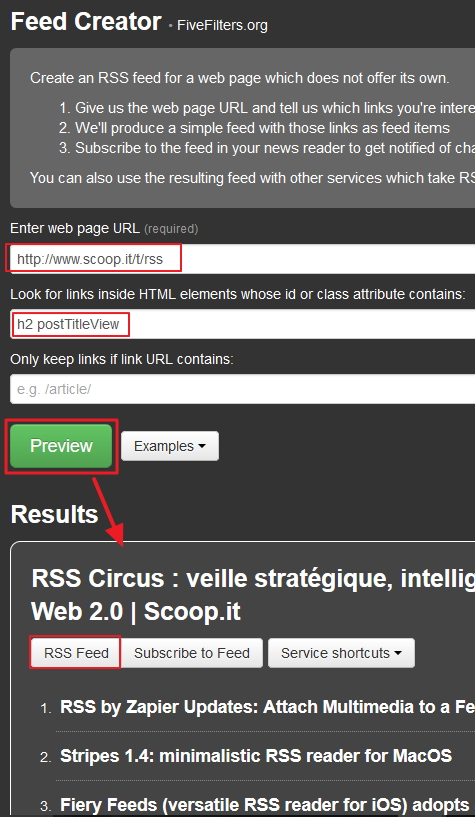
On clique ensuite sur « preview » puis sur « RSS Feed » pour récupérer le flux en question.
La bonne nouvelle c’est que le flux créé fonctionne parfaitement (testé avec Inoreader), la mauvaise c’est que malheureusement il n’intègre pas tous les items (articles) publiés sur la page. Il manque en effet les articles de la colonne de droite de la page Scoop.it, c’est gênant. J’ai eu beau tenter de cibler précisément le type d’éléments manquants dans l’outil Firefox adéquat (ci-desous) je n’ai pas trouvé la solution.
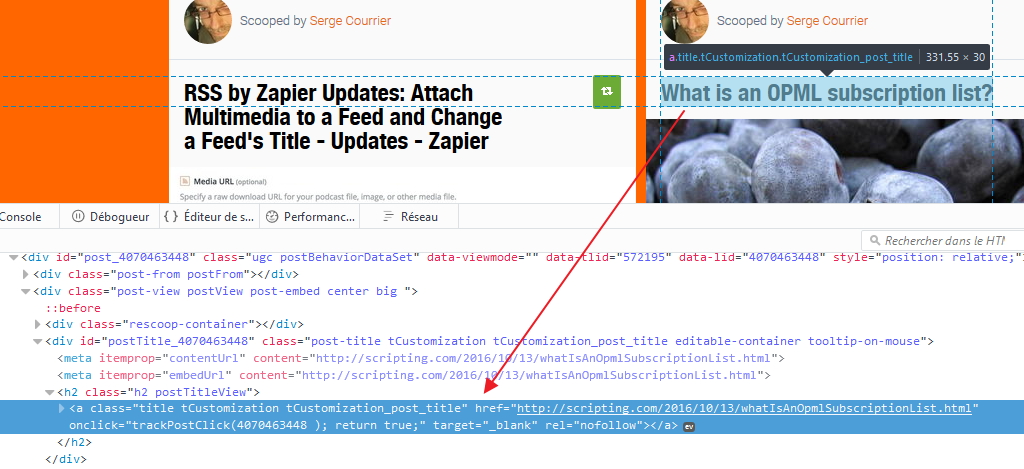
Bon je ne suis pas non plus un spécialiste du code alors si quelqu’un a une solution elle est la bienvenue 🙂
MàJ du 18/10/2016 : après une nuit d’attente (cf. commentaires ci-dessous) les nouvelles sont bonnes. En effet, les nouveautés sont bien intégrés dans le flux RSS généré par Fivefilters. La méthode fonctionne donc 🙂
Cher Christophe,
en fait, tu y étais presque (voir tu ne t’es pas trompé du tout, mais tu n’as pas assez attendu :-).
Quand tu effectues un clic droit sur un des titres « curationné » et que tu choisis « Examiner l’élément » (dans Firefox) ou « Inspecter » dans Chrome, tu peux plutôt te référer à la classe qui se trouve juste « en-dessous » de celle que tu avais trouvé. Soit
title tCustomization tCustomization_post_title
Une fois intégré dans fivefilters, cela donne (pour mon Scoop.it 🙂
http://createfeed.fivefilters.org/extract.php?url=www.scoop.it%2Ft%2Frss&in_id_or_class=title+tCustomization+tCustomization_post_title&url_contains=
Ne t’arrêtes pas au contenu du fil RSS tel que tu le visualises alors alors dans ton lecteur. Il se concentre en effet sur la première colonne. Mais tout nouvel article va s’ajouter correctement.
J’ai procédé ainsi pour suivre mon propre Scoop.it (histoire de valider la méthode) depuis le 6 septembre. Et ça marche !
Bien sûr si Scoop.it change de classe… il faudra tout réécrire.
Bref, si ça se trouve, ta méthode fonctionne tout aussi bien ! Il faut juste attendre les prochains articles !
Salut Serge,
Merci pour ta réponse rapide. J’avais aussi testé avec title tCustomization tCustomization_post_title mais comme çà ne semblait pas donner de résultats différents d’avec simplement title j’avais choisi de simplifier.
Pour ce qui est de l’incrémentation des nouveaux items je m’étais dit qu’en toute logique l’ordre antéchronologique devrait être respecté pour les prochains mais je n’ai pas eu le courage d’attendre.
Merci de me rassurer donc 🙂
J’attends les prochains résultats (au travail!) et je te dis ce que çà donne avec la classe que j’ai utilisé.
Bonsoir à vous 2,
Je ne m’étais pas encore penché sur Scoop.it, donc un grand merci Christophe.
Du coup, j’ai approfondi un peu. Pour avoir également le commentaire d’un scoop, voici l’URL à utiliser, qui intègre les bons paramètres (fonctionne chez moi) :
http://createfeed.fivefilters.org/extract.php?url=http://www.scoop.it/t/rss&item=.post-container-in-post-list&item_title=.h2.postTitleView&item_desc=.tCustomization.tCustomization_post_description
En changeant entre url= et &item par l’URL du scoop à surveiller.
Je vais mettre à jour ma page de flux RSS sur mon blog du coup 🙂
Bonne soirée !
Bryan
Autant, pour moi, le bon URL est :
http://createfeed.fivefilters.org/extract.php?url=http://www.scoop.it/t/rss&item=.post-container-in-post-list&item_title=.h2.postTitleView&item_desc=.tCustomization.tCustomization_post_description&item_url=.title.tCustomization.tCustomization_post_title
(pour que les titres pointent vers la source et non vers l’auteur du scoop)
Intéressante amélioration. Merci Bryan
Réflexions supplémentaire.
> FEEDITY
Comme tu le dis, la solution gratuite est risquée dans la mesure où le rafraichissement ne se fait qu’une fois par jour, ne ramène que les 5 dernières actus et surtout, le fil se désactive s’il n’y a rien eu de neuf depuis 7 jours sur la page. Ce qui peut arriver dans un Scoop.it peu actif.
> FEED43
Pour la version gratuite, le code de la page d’accueil est trop long. Il dépasse les 100 Ko autorisés.
> FETCHRSS.
Il détecte très proprement la page et permet même de récupérer les images, textes, sources et dates de publication associés au scoops. Mais il a les mêmes limites que Feedity. En revanche la version payante est moins chère.
> FIVEFILTERS
Rappelons qu’une version à héberger soi-même est disponible pour 20€, qui ouvre le droit à une mise à jour par an, et permet de l’utiliser (mais sans mise à jour) au-delà de cette durée.
Merci pour ces infos complémentaires Serge.
Avant d’écrire ce billet j’ai testé FetchRSS que j’aime beaucoup mais qui ne fonctionnait pas sur la page Scoop.it. J’ai également tenté Feed43 qui est effectivement bloqué par la taille de la page (et que je trouve trop complexe de toutes façons). J’ai testé pour finir la version desktop de Kimono qui, quelques mois après son lancement, ne fonctionne plus du tout…
Avec la même méthode (sous Fivefilters), nous pouvons donc aussi récupérer les scoops liés à un tag sur un « topic » particulier.
Un exemple d’URL lié à un tag : http://www.scoop.it/t/rss/?tag=2RSS
Cool, merci Serge.
Bonjour,
Je souhaite créer une revue de presse via l’insertion de flux RSS sur scoop it pour ma bibliothèque. Malgré vos explications qui sont fort intéressantes, je n’arrive pas à insérer de flux RSS avec vos méthodes dans scoop it. Peut-être est-ce à dû au fait que je possède une version gratuite de scoop it?
Merci d’avance.
Amandine
Bonjour,
En fait la méthode que j’indique ici sert à créer un flux RSS pour une page Scoop.it afin d’être prévenu des nouveaux éléments qui y sont ajoutés par la personne qui la gère, le curateur donc. Le flux RSS ainsi créé devra ensuite être ajouté dans un agrégateur de flux comme Inoreader afin d’être lu.
Vous pouvez utiliser Scoop.it comme agrégateur de flux mais, comme vous le supposiez, uniquement dans sa version payante.
Bonjour,
Est-ce que ça fonctionne toujours chez vous ?
En décembre, mes tests étaient bons, aujourd’hui j’ai
– sur feedly j’ai -> No feeds with matching titles.
– sur fivefilters j’ai -> Failed!
Bonjour,
Je n’ai pas refait le test sur Feedity (et pas Feedly hein) mais je l’ai refait sur Fivefilters et en suivant les étapes données dans l’article çà fonctionne sans problème.
Bonne journée,
Christophe
Bonjour,
j’ai tenté avec Fivefilters pour cette page que je suis pour ma veille : http://www.scoop.it/t/questions-de-developpement
Ça ne fonctionne ni avec h2 postTitleView, ni avec title, ni avec title tCustomization tCustomization_post_title
Y a-t-il une explication ?
Merci.
BIzarre ce que vous me dites 😕 Je viens de faire le test avec votre page Scoop.it et ça a bien fonctionné. Voici le flux créé : http://createfeed.fivefilters.org/extract.php?url=www.scoop.it%2Ft%2Fquestions-de-developpement&in_id_or_class=h2+postTitleView&url_contains=
Bonjour.
Bizarre effectivement. Je viens de réessayer à nouveau sans succès. J’obtiens à chaque fois :
Failed!
Submitted parameters (
[url] => http://www.scoop.it/t/questions-de-developpement
[in_id_or_class] => h2 postTitleView
[url_contains] =>
)
Merci pour le flux créé, mais autre problème : je ne parviens pas à le lire avec Netvibes.
Idem pour moi, avec aucune des solutions proposés je n’obtiens de résultat, les exemples d’URL renvoie également vers une erreur… Scoop.it aurait-il trouvé une parade ?
Moi aussi, quoique je fasse, « failed ».
Sans doute y a plus moyen…
Auitre idée: avec les parser de Zapier..?
La méthode semble de nouveau marcher. Avez vous une idée cependant de comment je pourrais ajouter la date de l’article ou du scoop sur le flux rss ? Je cherche à intégrer la flux sur le logiciel Hootsuite qui demande pour flux minimum un titre et une date.
Merci d’avance.
Incompréhensible : il y a quelques mois la méthode avec FiveFilters fonctionnait très bien et aujourd’hui en pleine démo en formation, je n’ai que des « failed ! » qui s’affichent… J’ai testé sur 2 navigateurs : Firefox et Chrome. Et j’ai aussi testé avec plusieurs pages Scoop.it Est-ce que d’autres peuvent essayer pour me dire si c’est général ou si c’est un problème local ?
Bonsoir Angie,
Je viens de tester le lien que j’ai partagé plus haut, cela fonctionne toujours bien chez moi :
http://createfeed.fivefilters.org/extract.php?url=http://www.scoop.it/t/rss&item=.post-container-in-post-list&item_title=.h2.postTitleView&item_desc=.tCustomization.tCustomization_post_description&item_url=.title.tCustomization.tCustomization_post_title
Bonne soirée,
Bryan